Под колпаком
Под колпаком
“Люди-хабы”, подвергающие риску и себя, и своих партнеров, – главные разносчики половых инфекций, однако существует математический прием, позволяющий использовать их самих и структуру сети, чтобы попытаться остановить распространение болезни.
Идея станет понятна, если мы представим себе упрощенную сеть:
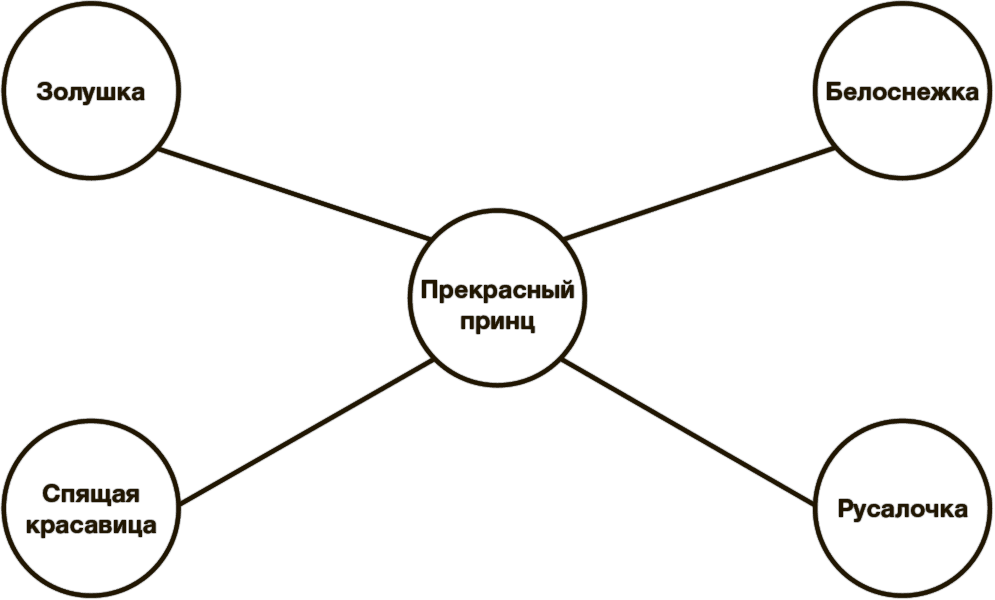
Допустим, у нас есть четыре юные принцессы: Золушка, Белоснежка, Русалочка и Спящая красавица. Все они предаются любви с одним и тем же весьма сексуальным Прекрасным принцем и соответственно образуют сеть сексуальных контактов. При этом между дамами никаких сексуальных контактов нет (мы не будем учитывать то, что пишут на некоторых весьма смелых диснеевских фансайтах, и я настоятельно советую вам не посещать такие места, если вы хотите сохранить в чистоте свои невинные детские воспоминания).
Теперь представим, что среди членов группы завелась какая-то неприятная инфекция. Если вакцинация или просвещение каждого члена группы обойдется слишком дорого, мы можем сосредоточиться только на “узле”, как ключевом элементе сети.
Однако, не видя скрытых связей внутри сети, мы сможем понять, что этот человек – Прекрасный принц, только когда опросим всех участников, сколько у каждого из них сексуальных партнеров. Таким образом, задача состоит в том, чтобы, не зная всех участников сети, с наибольшей вероятностью выявить скрытый “узел”.
Если мы выберем кого-то наугад, то шансы, что мы сразу угадаем “хаб”, составляют один к пяти. Но представьте, что вместо этого мы выберем первого попавшегося участника, скажем, Русалочку, и попросим ее помочь нам сделать прививку своему партнеру. Русалочка приведет нас к Прекрасному принцу. Точно так же, если мы случайным образом выберем Золушку и обратимся с той же просьбой, она тоже выведет нас на Принца. Так же поступят Спящая красавица и Белоснежка.
Иными словами, добавив к нашему алгоритму один простой шаг, мы увеличим наши шансы обнаружить “узел” сразу в четыре раза: до четырех шансов из пяти. Гораздо лучше, не так ли?
То же самое относится и к гораздо более обширным сетям. Представьте, что, мы, не имея доступа к статистике Twitter, попытаемся отыскать Кэти Перри – самый большой “хаб” этой социальной сети (на момент написания данной главы).
Если мы возьмем наугад одного из 500 миллионов пользователей Twitter, то наш шанс найти Кэти составит один на 500 миллионов.
Если мы столь же случайным образом выберем пользователя и попросим его назвать нам самого популярного человека, на которого он подписан, то таких может набраться уже 57 миллионов. Внезапно наши шансы найти Кэти подскакивают до 10 % и выше, что очень впечатляет, особенно учитывая, насколько прост алгоритм.
Подобная методика используется для прогнозирования и остановки эпидемий, избавляя медиков от необходимости проводить сложное и дорогое выявление всей сети заболевших. А кроме того, такие расчеты, как мне кажется, рассказывают нам что-то очень важное о том, как просто устроена обширная сеть, которая соединяет всех нас.
Так что в следующий раз, занося новый трофей в свой донжуанский список, подумайте об огромной разветвленной сети, частью которой вы становитесь. Математики не в состоянии помочь вам повысить качество секса, но мы пытаемся – и нам это удается – сократить число инфекционных заболеваний, которые вы можете подхватить.
И разве это само по себе уже не секси?
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.