Глава 1. Что такое искусственный интеллект
Глава 1. Что такое искусственный интеллект
Существует довольно много научно-фантастических фильмов, в которых действуют автономные машины, способные самостоятельно принимать решения. Но каково в действительности развитие искусственного интеллекта? Неужели и правда близок тот час, когда мы своими глазами сможем увидеть картины, изображенные в «Космической одиссее 2001 года» или в фильме «Я, робот»?
Прежде чем начать наш рассказ, дадим точное определение искусственному интеллекту. Трактовка слова «искусственный» разногласий не вызывает: «искусственный» означает «не природный», то есть «созданный по воле человека». А что такое «интеллект»? Согласно большинству словарей, это слово имеет множество значений, среди которых выделяются «способность понимать», «способность решать задачи», «способность учиться из опыта и адаптироваться к новым ситуациям».
И различные определения этого понятия показывают всю его сложность.
Психологи и философы пытаются определить и измерить интеллект на протяжении многих веков. Но все предложенные ими определения довольно трудно применить не к людям, а к другим объектам. К примеру, обладает ли интеллектом компьютерная программа, способная синхронизировать и координировать работу всех систем самолета, позволяющая со стопроцентной надежностью прокладывать курс в зависимости от текущих требований? Возможно, что да. Но можно ли сказать, что интеллектом обладает комар? Это насекомое ведь тоже способно синхронизировать и координировать работу всех своих органов и со стопроцентной надежностью прокладывать курс в зависимости от текущих требований.
Тест Тьюринга
Практическое решение, позволяющее определить, обладает ли машина интеллектом, первым предложил в 1950 году математик Алан Тьюринг, который считается одним из создателей искусственного интеллекта. В основе его теста лежит очень простая идея: если машина во всем ведет себя подобно мыслящему существу, то она должна обладать интеллектом.
Тест Тьюринга проводится следующим образом. Человек и машина располагаются в разных комнатах и не могут видеть друг друга. После этого человек печатает на клавиатуре ряд вопросов для машины, а та выдает на монитор ответ. Если человек считает, что беседует с человеком, то оцениваемая им машина разумна и, следовательно, обладает искусственным интеллектом.
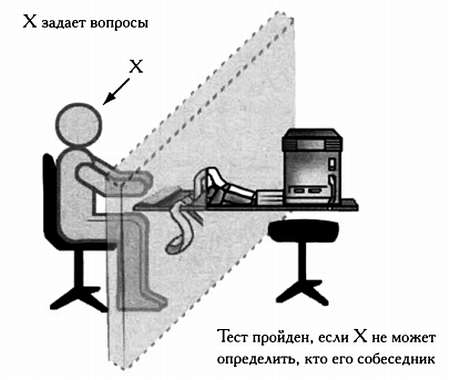
Человек, задающий вопросы машине (X), использует систему, препятствующую визуальному контакту. Таким образом, он может определить, кто его собеседник — машина или человек — только по ответам на вопросы.
Разумеется, тест Тьюринга вызвал шквал критики со стороны некоторых теоретиков. Можно ли сказать, что машина разумна, только потому, что она способна отвечать на вопросы с помощью огромного словаря вопросов и ответов? Быть может, интеллект — это нечто большее, и он подразумевает, к примеру, наличие сознания?
* * *
АЛАН ТЬЮРИНГ (1912–1954)
Английский математик и философ Алан Тьюринг благодаря множеству фундаментальных открытий считается одним из создателей не только искусственного интеллекта, но и всей современной информатики.
Во время Второй мировой войны Тьюринг занимался криптоанализом и стал одним из главных действующих лиц в операции по взлому шифров машины «Энигма». Успешное завершение этой операции позволило союзникам узнавать обо всех перемещениях нацистских войск.
Основным теоретическим вкладом Тьюринга в вычислительные науки стала так называемая машина Тьюринга — теоретическая модель универсальной вычислительной машины, способной обрабатывать любые входные данные и получать выходное значение за конечное время. Машина Тьюринга состоит из бесконечной ленты с записанными на ней символами, а также управляющего устройства, которое может смещаться вдоль ленты вправо или влево, считывать записанные на ней символы, стирать их и записывать новые. Также машина Тьюринга содержит правила, определяющие действия управляющего устройства для любого символа, записанного на ленте. В практической информатике эти правила соответствуют компьютерной программе, а лента — системе ввода-вывода и регистру о состоянии выполнения программы.
Сегодня при создании новых языков программирования, например С, Pascal, Java и других, прежде всего нужно доказать, что они являются Тьюринг-полными, то есть эквивалентны машине Тьюринга.
Ученый покончил с собой, не выдержав преследования британских властей. На суде Тьюринг отказался от адвоката, сочтя, что ему не в чем оправдываться, и был признан виновным, что в конечном итоге привело его к самоубийству. В 2009 году Гордон Браун, который в то время занимал пост премьер-министра Великобритании, публично принес извинения от имени британского правительства за преследования, которым подвергся Алан Тьюринг в последние годы жизни.

* * *
Главным критиком теста Тьюринга стал философ Джон Сёрль, предложивший эксперимент под названием «китайская комната». Представьте себе, что человек, не знающий ни слова по-китайски, помещен в закрытую комнату в торговом центре Шанхая. Посетителей торгового центра приглашают задать этому человеку вопросы, записав их на бумаге и передав записку через специальное отверстие. Под рукой у человека в закрытой комнате находится словарь, в котором указаны все китайские иероглифы, содержащиеся во всех возможных вопросах, которые только могут задать посетители. Молодой человек снаружи пишет на листе бумаги вопрос на китайском языке: «Там внутри тепло?» и просовывает записку в комнату. Человек внутри смотрит на иероглифы, находит их в словаре и выбирает возможный ответ на вопрос. Далее он перерисовывает нужные иероглифы на новый лист и возвращает ответ автору вопроса. Ответ на китайском языке звучит так: «Нет, вообще тут очень холодно». Логично, что и задающий вопрос молодой китаец, и остальные участники эксперимента получат корректные ответы на своем родном языке и сочтут, что человек в запертой комнате прекрасно владеет китайским. Однако на самом деле все ответы были составлены на основе словаря соответствий, а запертый человек не понял ни единого иероглифа.
Может ли произойти так, что машина, которая пройдет тест Тьюринга, обманет нас, как человек, сидящий в китайской комнате? Нет, это невозможно. «Китайская комната» — некорректный эксперимент: в нем люди, сидящие в комнате, не знают китайского, но отвечают на вопросы с помощью руководства, созданного кем-то, кто знает китайский и смог составить полный перечень вопросов и ответов.
Сегодня новая технология считается интеллектуальной, если она позволяет решить задачу творчески, что всегда считалось исключительной способностью человеческого мозга. Ярким примером технологии, которая кажется интеллектуальной, но не считается таковой, являются первые экспертные системы, созданные в 1960-е годы. Экспертная система — это компьютерная программа, реализованная по определенным сложным правилам, которая может автономно осуществлять контроль над другими системами. Примером можно считать компьютерную программу с огромным списком симптомов различных заболеваний, на основе которых она может назначить нужное лечение. Тем не менее такая система неспособна вывести новое правило из уже известных или при необходимости предложить нестандартную терапию. Следовательно, эта система не обладает креативностью и ее нельзя назвать интеллектуальной.
Интеллектуальная компьютерная система удовлетворяет отчасти субъективным требованиям: так, она должна иметь возможность обучаться, уметь оптимизировать математические функции со множеством параметров (измерений) на огромном интервале (области определения) или планировать использование огромного объема ресурсов с учетом ограничений.
Подобно остальным областям науки и техники, со временем в искусственном интеллекте возникли специализированные дисциплины и были выделены пять больших разделов.
1. Поиск.
2. Обучение.
3. Планирование.
4. Автоматические рассуждения.
5. Обработка естественного языка.
В разных областях искусственного интеллекта применяются порой одни и те же технологии и алгоритмы. Расскажем о каждом из разделов подробно.
* * *
МОЖНО ЛИ СЫМИТИРОВАТЬ ИНТЕЛЛЕКТ? ШАХМАТЫ, КАСПАРОВ И DEEP ВLUЕ
Шахматы — классическая комбинаторная задача, для решения которой с самого момента создания информатики безуспешно предпринимались попытки применить интеллектуальные методы, позволившие бы компьютеру одержать победу над игроками-людьми. Почему же нельзя сымитировать интеллект в такой игре, как шахматы? Представьте, что мы ввели в компьютер правила игры и он построил множество всех возможных ходов. Далее мы можем последовательно определить оптимальный ход в каждой возможной позиции. Число возможных ходов имеет порядок 10123, и это больше, чем количество всех электронов во Вселенной! Следовательно, только для хранения результатов объем памяти компьютера должен превышать Вселенную! Как видите, в примере с шахматами, в отличие от «китайской комнаты», сымитировать интеллект при помощи перечня всех возможных ходов абсолютно невозможно.
Наибольшую известность среди всех шахматных компьютеров приобрел компьютер Deep Blue и его противостояние с Гарри Каспаровым. Суперкомпьютер Deep Blue, запрограммированный для игры в шахматы, в 1996 году впервые в истории обыграл чемпиона мира. Вначале в шести партиях победу одержал Каспаров со счетом 4:2. Чемпиону противостояла машина, способная анализировать 100 миллионов ходов в секунду. Затем против Каспарова выступила вторая версия компьютера, Deeper Blue, способная анализировать уже 200 миллионов ходов в секунду. На этот раз победу одержал компьютер, однако Каспаров был уверен, что в определенный момент машине все же помог человек. Ситуация выглядела так: Каспаров пожертвовал пешку, чтобы затем начать контратаку. Компьютер не мог обнаружить эту ловушку, так как его расчеты распространялись на ограниченное число ходов вперед и он не мог увидеть зарождающуюся контратаку Каспарова.
Однако машина не поддалась на эту уловку, что вызвало у шахматиста подозрения. После завершения партии он попросил обнародовать протоколы операций, выполненных компьютером. Компания IBM ответила согласием, однако в конечном итоге протоколы так и не были представлены публике.

Созданный компанией IBM суперкомпьютер Deep Blue, одержавший победу над чемпионом мира по шахматам.
Поиск
Под поиском здесь понимается поиск оптимального решения определенной задачи.
После определения задачи с помощью математической функции речь пойдет об оптимизации функций, то есть о поиске входных параметров, при которых результирующее значение будет оптимальным. Для решения некоторых задач требуется оптимизировать несколько функций одновременно, при этом определить эти функции и ограничить их значения непросто. Для автоматической системы оптимизация функций представляет сложную задачу, особенно если функция не задана аналитически и ее примерный вид можно определить лишь на основе нескольких множеств значений. Часто бывает, что рассматриваемая функция имеет несколько сотен параметров, либо вычисление множеств ее значений очень трудоемко, либо множества ее значений содержат шум, то есть в определенных точках пространства являются неточными.
В подобных сложных сценариях используется искусственный интеллект. Человек способен решать сложные многомерные математические функции благодаря интуиции — классическим примером служат функции подобия. Представьте, что вам знакомы более 500 человек. Если вы увидите фотографию какого-то человека, то мгновенно сможете сказать, знаком ли он вам, и даже назвать его имя. Эта с виду простая операция решается путем оптимизации функции, описывающей разницу между лицами, которые вы помните, и изображенным на фотографии. Каждое лицо описывается тысячами параметров: цвет глаз, соотношение размеров рта и носа, наличие веснушек и так далее. Наш мозг способен определять все эти характеристики и сравнивать их с характеристиками всех знакомых нам людей. Мозг оценивает параметры лица на фотографии, сравнивает их с параметрами лиц всех знакомых людей и определяет, для какого человека различие между этими параметрами будет наименьшим. Также мозг определяет, когда различие между параметрами настолько мало, что можно сказать: на фотографии изображен один из знакомых людей. И все эти операции мозг выполняет менее чем за секунду. Однако для компьютера распознавание лиц — крайне сложная операция, и ему для решения этой же задачи потребуется несколько минут.
* * *
ГО — ОДНА ИЗ ВЕЛИЧАЙШИХ НЕРЕШЕННЫХ ЗАДАЧ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Игра го — прекрасный пример комбинаторной задачи, в которой выбор оптимального хода в заданной позиции вполне по силам даже игроку среднего уровня, но крайне сложен для компьютера.
Сегодня еще ни одна компьютерная программа не смогла без форы обыграть профессионального игрока в го.
Правила этой стратегической китайской игры крайне просты, однако по ходу партий постоянно возникают невероятно сложные сценарии. В го играют на доске, разделенной линиями на квадраты размером 19 х 19. Два игрока по очереди ставят фишки белого и черного цвета на свободные пересечения линий доски. Если одна или несколько фишек оказываются полностью окруженными фишками другого цвета, то «захваченные» фишки снимаются с доски. Игрок может в любой момент передать право хода противнику, но если оба они передают право хода два раза подряд, партия заканчивается, и победителем признается тот, кто на момент прекращения партии имел более выгодную позицию.
С точки зрения математики го — стратегическая игра, подобная шахматам. Однако если компьютер все же оказался способен одержать верх над чемпионом мира по шахматам, то программы для игры в го едва ли одолеют игрока-любителя. Происходит это по трем причинам. Во-первых, доска для игры в го более чем в пять раз просторнее шахматной доски, следовательно, потребуется проанализировать большее число ходов. Во-вторых, каждый ход может повлиять на несколько сотен последующих, поэтому компьютер не может прогнозировать развитие партии в долгосрочной перспективе. Наконец, в шахматах фигуры снимаются с доски по одной и обладают определенной ценностью, поэтому можно довольно точно оценить выгоду оттого или иного хода. В го, напротив, выгода, получаемая от взятия фишки соперника, зависит оттого, какие именно фишки снимаются с доски, что определяется их текущим расположением.
Доска и фишки для игры в го. Последние традиционно называются камнями.
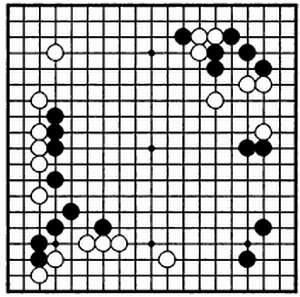
Положение фишек на доске в одной из партий финала чемпионата мира, прошедшего в 2002 году, где встретились Чхве Мёнхун (белые) и Ли Седоль.
* * *
Почему мы называем этот раздел искусственного интеллекта поиском, если речь идет о численной оптимизации? К поиску относятся задачи и другого типа, к примеру, так называемые комбинаторные задачи. Их решения образованы различными элементами, которые могут сочетаться между собой и порождать комбинаторное пространство. Решение такой задачи определяется оптимальным множеством элементов. Хороший пример комбинаторной задачи — шахматная партия. Оптимальным решением этой задачи будет последовательность ходов, ведущих к выигрышу.
Еще один классический пример — так называемая задача о ранце, в которой нужно уложить в рюкзак различные предметы. В этом случае решением будет совокупность предметов с минимальным общим весом и максимальной ценностью. И вновь комбинаторная задача, относительно простая для человека, часто оказывается крайне сложной для компьютера.
Одна из множества информационных систем, используемых для распознавания образов, в данном случае — для распознавания лиц. На иллюстрации изображена разработка японской компании NEC.
Обучение
Следующий раздел искусственного интеллекта — обучение. Является ли интеллектуальной система, способная обучаться на основе предшествующего опыта? Вернемся к примеру с автоматической системой диагностирования, в которую введено множество симптомов, соответствующих определенным заболеваниям. Этот процесс ввода информации, содержащей различные внутренние связи, называется обучением. После того как система обучена, она способна найти в памяти любой симптом и определить, какое заболевание ему соответствует. Обучение такой системы основано на запоминании, и ее нельзя назвать интеллектуальной. Цель обучения интеллектуальных систем — сформировать способность формулировать обобщения, то есть выводить некие правила, которые затем можно будет применить для решения новых задач.
Автоматическое обучение стало одним из самых обширных разделов искусственного интеллекта. В университетах, исследовательских центрах и компаниях ежедневно совершаются новые открытия в этой области, ведь, с одной стороны, в различных областях знаний и промышленности очень велика потребность в экспертных системах, а с другой — программировать полезные экспертные системы очень сложно.
Обучение интеллектуальной экспертной системы производится на основе последовательности случаев и соответствующих им решений. После обучения система способна выводить правила и нормы, описывающие исходные случаи, и для любого нового случая она сможет найти новое решение. Экспертную систему можно считать интеллектуальной, только если она умеет автоматически обучаться и формулировать обобщения. Иными словами, система не должна требовать ручного ввода правил, а после обучения она ведет себя подобно эксперту в своей предметной области.
Позднее мы расскажем о способах применения экспертных систем более подробно. Мы приведем несколько показательных примеров современных экспертных систем, например систем, используемых для прогнозирования просрочки платежей по ипотеке, систем раннего обнаружения злокачественных опухолей или систем автоматической классификации нежелательных электронных писем (спама).

Автоматическая классификация электронной почты с целью отделить спам от корректных сообщений — одна из областей применения экспертных систем.
Планирование
Третий крупный раздел искусственного интеллекта — планирование. Человек обладает способностью строить планы с незапамятных времен. Можно сказать, что человек и выжил-то благодаря планированию. Если мы перенесемся в палеолит, то и там встретимся с проблемой, требующей планирования: как распределить наличный объем пропитания между числом потребителей — членов племени? Кому отдать сочное мясо, богатое калориями: тем, кто собирает ягоды, или охотникам?
А если один из собирателей — женщина на последних месяцах беременности? Все эти вопросы соответствуют так называемым ограничениям системы, то есть обстоятельствам, которые следует учитывать при составлении плана.
Ограничения делятся на обязательные и необязательные. В нашем примере с доисторическим племенем лучшие куски мяса должны доставаться тем, кто больше всего нуждается в этом. Однако не случится ничего страшного, если самому сильному охотнику в один из дней не достанется самый сочный кусок. Конечно, эта ситуация не может повторяться постоянно, но уж один-то день охотник может потерпеть.
Следовательно, это необязательное ограничение.
В качестве примера обязательного ограничения приведем распределение ресурсов университета (то есть аудиторий и преподавателей) в течение учебного года. Потребителями ресурсов будут студенты, изучающие, например, математический анализ, торговое право, физику и другие предметы. При распределении ресурсов нужно учесть, что студенты, изучающие торговое право и физику, не могут одновременно занимать, например, аудиторию 455. Заведующий кафедрой математического анализа также не может преподавать торговое право, так как не имеет необходимой квалификации. В этом примере описанные ограничения являются обязательными.
Таким образом, при разработке интеллектуального алгоритма планирования важнейшую роль играет возможность или невозможность нарушить накладываемые ограничения.
* * *
ЗАДАЧА КОММИВОЯЖЕРА
Порой определенная задача может быть отнесена к тому или иному разделу искусственного интеллекта в зависимости оттого, с какой стороны мы подойдем к ее решению. Хорошим примером является задача коммивояжера (Travelling Salesman Problem, или TSP), которую можно решить путем поиска или планирования.
Формулировка этой задачи звучит так: для данного множества городов, дорог между ними и расстояний нужно найти маршрут коммивояжера, проходящий через все города. Коммивояжер не может заезжать в один и тот же город дважды и при этом он должен преодолеть наименьшее расстояние. Как читатель может догадаться, в зависимости от расположения маршрутов между городами коммивояжер обязательно посетит какой-либо город дважды, следовательно, это условие можно считать несущественным.
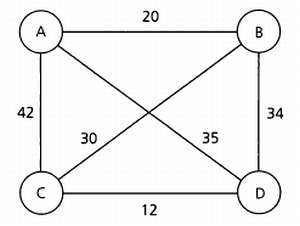
Пример графа городов, связанных между собой. Расстояние между городами в километрах указано на ребрах графа.
Автоматические рассуждения
Четвертый раздел искусственного интеллекта — автоматические рассуждения.
Именно они привлекают наибольшее внимание широкой публики и часто становятся главной темой научной фантастики. Тем не менее автоматическим рассуждениям как отдельной дисциплине дала начало не слишком увлекательная задача об автоматическом доказательстве математических теорем.
Часто выдвигаются новые теоремы, которые требуется доказать или опровергнуть. Доказательство теорем может быть крайне сложным. Именно это произошло с великой теоремой Ферма (согласно ей, если n — целое число, большее двух, то несуществует ненулевых натуральных чисел, удовлетворяющих равенству zn = хn + уn) — на доказательство этой теоремы ушло более 200 лет!
В 1956 году экономист Герберт Саймон (1916–2001) и инженер Аллен Ньюэлл (1927–1992) совместно разработали машину под названием Logic Theorist, способную доказывать нетривиальные теоремы математической логики. Разумеется, появление этой машины стало вехой в развитии искусственного интеллекта и вновь вызвало философскую дискуссию о возможности создания мыслящих машин. Эта дискуссия, конечно же, повлияла на литературу и кино 1960—1970-х годов, породив образы мыслящих машин, враждебных человеку. Согласно философу Памеле МакКордак, Logic Theorist доказывает: машина способна выполнять задачи, которые cчитаются творческими и подвластными исключительно человеку.

Гэрберт Саймон (слева) и Аллен Ньюэлл за игрой в шахматы, 1958 год.
В Logic Theorist использовались так называемые символьные системы, созданные математиками, чтобы придать смысл некоторым выражениям и уйти от произвольных обозначений. К примеру, мы можем утверждать: высказывание «быть человеком» означает «быть смертным», что можно записать математически как А —> В, где символ А эквивалентен высказыванию «быть человеком», символ —> — «означает», а В равносильно высказыванию «быть смертным». «Быть человеком означает быть смертным» — это произвольное высказывание, которое записывается выражением А —> В. После формализации всех произвольных членов выполнять операции с ними намного проще с точки зрения математики и информатики.
Для упрощения математических действий символьные системы опираются на аксиомы, из которых выводятся теоремы. Преимущество символьных систем в том, что они являются формальными и однозначно определенными, поэтому программировать их сравнительно просто. Рассмотрим пример:
Сократ — человек.
Все люди смертны.
Следовательно, Сократ смертен, поскольку он — человек.
Если мы запишем эти высказывания в формальном виде, они будут выглядеть так:
А: Сократ
В: человек (люди)
А —> В
С: смертен (смертны)
В —> С
Если А —> В и В —> С, то А —> С, то есть Сократ смертен.
В этом случае правило вывода под названием «гипотетический силлогизм» позволяет заключить, что А —> С истинно, если А —> В и В —> С.
Тем не менее число вариантов, полученных при автоматическом и систематическом выводе теорем на основе аксиом и правил вывода, будет опасно близко к числу атомов во Вселенной. По этой причине в машине Logic Theorist использовались эвристические рассуждения, то есть методы нечеткого прогнозирования, которые помогали выбрать лучшие производные высказывания среди возможных. Отобранные высказывания определяли правильную последовательность выводов, позволявших прийти от аксиом к доказательству теорем.
Рассмотрим практический пример. Мы хотим знать, смертен ли Сократ. Нам известны следующие исходные аксиомы:
А: Сократ
В: болельщик «Олимпиакоса
С: грек
D: человек
Е: смертен
А —> С
С —> D
A —> D
С —> Б
D —> E
Определим, истинно или ложно А —> Е, с помощью «грубой силы», то есть путем перебора всех возможных сочетаний. Имеем:
А —> С —> D —> Е
A —> С —> В
A —> D —> E
Мы выполнили семь логических операций, взяв за основу всего пять аксиом и одно правило вывода — гипотетический силлогизм. Легко догадаться, что в сценариях, содержащих больше аксиом и правил вывода, число возможных сочетаний может оказаться столь велико, что на получение доказательств уйдут годы. Чтобы решить эту проблему так, как это сделали Саймон и Ньюэлл, используем эвристическое рассуждение (или эвристику). В нашем примере эвристика подскажет: если мы хотим доказать, что некий человек смертен, нет необходимости заводить разговор о футболе (А —> С —> В).
И символьные, и эвристические системы широко используются для решения практических задач, а не только для автоматического доказательства теорем.
Приведем еще один пример использования эвристик. На каждом ходу в шахматной партии существует в среднем 37 возможных вариантов. Следовательно, если компьютерная программа будет анализировать партию на восемь ходов вперед, на каждом ходу ей придется рассмотреть 378 возможных сценариев, то есть 3512479453921 ходов — более 3,5 млрд вариантов. Если компьютер тратит на анализ каждого варианта одну микросекунду, то при анализе партии всего на восемь ходов вперед (достаточно простая задача для профессионального шахматиста) мощный компьютер будет думать над каждым ходом больше двух с половиной лет!
Для ускорения процесса нужны какие-то улучшения, которыми и будут эвристики. Эвристики — это правила прогнозирования, позволяющие исключить из рассмотрения ходы, которые ведут к очень невыгодной позиции и поэтому нецелесообразны. Уже благодаря тому, что эвристики позволяют исключить из рассмотрения несколько абсурдных ходов, число анализируемых вариантов существенно сокращается. Таким образом, эвристики — это средства прогнозирования, основанные на интуиции программиста, которые играют столь важную роль в большинстве интеллектуальных систем, что в значительной степени определяют их качество.
* * *
МАТЕМАТИЧЕСКАЯ ЛОГИКА
Математическая логика — раздел математики, занимающийся изучением схем и принципов рассуждений. Это дисциплина, в которой на основе различных правил и методов определяется корректность аргумента. Логика широко используется в философии, математике и информатике как средство проверки корректности имеющихся утверждений и вывода новых. Математическая логика была создана на основе аристотелевой логики Джорджем Булем, автором новой алгебры, которую впоследствии назвали булевой, и Огастесом де Морганом, сформулировавшим законы логики с помощью новой, более абстрактной нотации.
В последние 50 лет математическая логика пережила бурный рост, и на ее основе возникла современная логика, которую следует отличать от классической логики, или логики первого порядка. Формально логика первого порядка рассматривает только конечные выражения и правильно построенные формулы. В ней нет места бесконечным множествам и неопределенности.

Сколь бы сложными ни казались выражения, записанные на доске, в них очень редко используются символы, значение которых выходит за рамки логики первого порядка.
* * *
В последние годы непрерывно развиваются автоматические рассуждения, и теперь интеллектуальные системы способны рассуждать в условиях недостатка информации (неполноты), при наличии противоречивых исходных утверждений (в условиях неопределенности) или в случаях, когда при вводе новых знаний в систему объем совокупных знаний о среде необязательно возрастает (в условиях немонотонности).
Крайне мощным инструментом для работы в этих областях является нечеткая логика — разновидность математической логики, в которой высказывания необязательно абсолютно истинны или абсолютно ложны. Если в классической математической логике о любом высказывании всегда можно сказать, истинно оно или ложно (к примеру, ложным будет высказывание «некий человек не смертен», а истинным — «все люди смертны»), то в нечеткой логике рассматриваются промежуточные состояния. Так, если раньше говорили, что Крез не беден, это автоматически означало, что он богат, а если говорили, что Диоген не богат, это означало, что он беден (в этом примере классическая логика явно дискриминирует представителей среднего класса!). Применив нечеткую логику, мы можем сказать, что Аристотель богат со степенью, например, 0,6.
* * *
ДЖОРДЖ БУЛЬ (1815–1864) И ЕГО ЛОГИКА
Если Алана Тьюринга называют одним из отцов современной информатики, то Джорджа Буля можно назвать ее дедом. Этот британский философ и математик создал булеву алгебру — основу современной компьютерной арифметики, которая, в свою очередь, является фундаментом всей цифровой электроники.
Буль разработал систему правил, которые посредством математических методов позволяют выражать и упрощать логические задачи, в которых допускается только два состояния — «истина» и «ложь». Три основные математические операции булевой алгебры — это отрицание, объединение («или») и пересечение («и»). Отрицание, обозначаемое символом заключается в смене значения переменной на противоположное. К примеру, если А = «Аристотель — человек», то ¬А = «Аристотель — не человек». Объединение, обозначаемое символом v — это бинарная операция, то есть операция, в которой для получения результата требуются два аргумента. Результатом объединения будет истина, если один из двух аргументов истинный.
К примеру: «Верно ли, что сейчас вы либо читаете, либо ведете машину?». Ответом на этот вопрос будет «Да, верно», поскольку сейчас вы читаете эту книгу. Но если бы вы вели машину и не читали книгу, то ответ также был бы утвердительным. Он был бы утвердительным и в том случае, если бы вы, пренебрегая всеми соображениями безопасности, вели машину и читали эту книгу одновременно.
Третья операция — пересечение, обозначаемая символом
, также является бинарной. Если мы переформулируем предыдущий вопрос и скажем «Верно ли, что сейчас вы читаете и ведете машину?», то ответом будет «Да, верно» только в том случае, если вы будете читать за рулем.
На основе трех указанных операций можно определить другие, более сложные, например исключающее «или» (
 ), результат которой в нашем случае будет истинным только тогда, когда мы либо читаем книгу, либо ведем машину, но не выполняем оба эти действия одновременно. Операция
), результат которой в нашем случае будет истинным только тогда, когда мы либо читаем книгу, либо ведем машину, но не выполняем оба эти действия одновременно. Операция
не принадлежит к основным операциям булевой алгебры, так как ее можно выразить через три основные операции А
В = (А
¬ В) v (¬ А
В).
В цифровой электронике «истина» и «ложь» обозначаются единицей и нулем. Этим значениям соответствует наличие электрического тока в цепи (1) либо его отсутствие (0). Логические операции выполняются с помощью сочетаний транзисторов. Именно благодаря применению транзисторов в интегральных схемах в последние 40 лет информатика развивается столь быстрыми темпами.
Микропроцессор вашего домашнего компьютера, который можно назвать его мозгом, содержит сотни миллионов транзисторов, расположенных на площади всего лишь в несколько квадратных сантиметров!
Обработка естественного языка
Понимание человеческого языка и использование его при коммуникации — одна из важнейших нерешенных задач этой области знаний. Если искусственная система сможет понимать как языки программирования, так и человеческий язык, это поможет сделать машины более «человечными». Обработка естественного языка означает не только преобразование звуков в фонемы и письменные знаки, но и понимание смысла сообщаемых понятий (как в письменной, так и в устной форме) и выполнение с ними каких-либо действий.
Первые важные открытия в сфере обработки естественного языка совершил инженер Джозеф Вейценбаум (1923–2008), который в 1964–1966 годах разработал программу «Элиза». Пользователи могли задавать вопросы этой компьютерной программе, моделировавшей работу психотерапевта, а «Элиза», казалось, понимала их смысл, так как выдавала более или менее осмысленные ответы. Ниже приведена запись реального разговора между автором этой книги и «Элизой»:
Игнаси Белда: Мне нужен отпуск.
Элиза: Что означает для тебя отпуск?
Игнаси Белда: Я мог бы проводить больше времени с женой.
Элиза: Расскажи мне подробнее о своей семье.
Игнаси Белда: У меня есть только жена.
Элиза: Ты говоришь, что у тебя только одна жена?
Игнаси Белда: Да, я не полигамен.
Элиза: Ты кажешься позитивным.
Игнаси Белда: Мою жену зовут Лайа.
Элиза: А кто еще принадлежит к твоей семье?
Игнаси Белда: Больше никто.
Элиза: На самом деле никто?
Игнаси Белда: Да.
Элиза: Ты уверен?
Игнаси Белда: Абсолютно.
Как видите, настоящие психологи могут спать спокойно — «Элиза» еще не скоро сможет лишить их работы. Тем не менее с 1960-х годов обработка естественного языка развивается быстрыми темпами, и сегодня существуют методы решения столь разных задач, как определение плагиата, автоматический перевод текстов или очеловечивание интерфейсов взаимодействия людей и машин. Заинтересованный читатель может поговорить с «Элизой» на сайте http://www.chayden.net/eliza/Eliza.html.
И наконец, управление тем, что известно
Грамотное структурирование знаний крайне важно. Например, представим, что нас спросили, кто занимает должность мэра в американском городе Остин в штате Техас. Если мы не живем в этом регионе США, то наверняка сразу же ответим: «Не знаю». А система, в которой знания структурированы недостаточно хорошо, например любой персональный компьютер, потратит несколько минут на анализ всех документов на жестком диске, чтобы определить, не содержится ли в них имя мэра этого американского города. Интеллектуальная или псевдоинтеллектуальная система должна отвечать на этот вопрос так же быстро и четко, как человек. Для этого знания, хранящиеся в системе, должны быть четко структурированы и легко доступны.
При решении практических задач требуется не только грамотное структурирование знаний, но и наличие адекватных инструментов, позволяющих просматривать сохраненные знания и поддерживать их в упорядоченном виде. Именно эту базу знаний система использует в качестве основы при автоматических рассуждениях, поиске, обучении и так далее. Следовательно, база знаний интеллектуальной системы изменяется, поэтому интеллектуальным системам необходимы средства контроля знаний, которые, к примеру, позволят разрешать возможные противоречия, устранять избыточность и даже обобщать понятия.
Чтобы четко контролировать знания, содержащиеся в базе, необходима метаинформация, описывающая их внутреннее представление. Знать, как представлены знания, очень важно, так как они могут быть структурированы множеством способов, и информация о структуре хранимых знаний может оказаться крайне полезной.
Следует учитывать и разграничение знаний: при работе с нашей базой знаний будет полезна информация о том, какие области и в какой мере эта база охватывает.
Человек легко справится с неполнотой знаний, но информационной системе необходимо очень четко указать, что ей известно, а что — нет. Поэтому одним из первых методов управления базами знаний стало допущение замкнутости мира (англ. CWA — Closed World Assumption). Это допущение предложил Раймонд Рейтер в 1978 году. Он взял за основу простое утверждение, которое, однако, имело важные последствия: «Единственные объекты, которые могут удовлетворять предикату Р, — те, что должны удовлетворять ему». Иными словами, все знания, не зафиксированные в системе, неверны.
Допустим, нас спросили, работает ли некий человек в определенной компании.
Чтобы узнать ответ, мы обращаемся к списку сотрудников, и если нужного человека в списке нет, то говорим, что он не работает в компании.
Допущение замкнутости мира в свое время существенно упростило работу с базами знаний. Однако читатель наверняка догадался, что это допущение имеет важные ограничения: если в реальной жизни нам неизвестен какой-либо факт, это не означает, что он автоматически будет ложным. Вернемся к примеру со списком сотрудников компании. Возможно, человек, работающий в организации, не указан в списке по ошибке или потому, что список устарел? Еще один недостаток допущения замкнутости мира заключается в том, что при работе с ним необходимо использовать чисто синтетические рассуждения.
Представьте, что у нас есть следующих список одиноких людей и людей, состоящих в браке:
Холост (-а) Хуан
Холост (-а) Мария
В браке Давид
Если кто-то спросит систему, холост ли Хорхе, система ответит отрицательно, так как Хорхе нет в списке холостяков. Составим новый список вида:
Не в браке Хуан
Не в браке Мария
В браке Давид
Вновь спросим систему, женат ли Хорхе, и вновь получим отрицательный ответ.
Система не содержит информации о семейном положении Хорхе, поэтому она позволяет сделать противоречивый вывод: Хорхе не одинок и вместе с тем не состоит в браке. Очевидно, что допущение замкнутости мира некорректно применять при неопределенности знаний или в случае их неполноты, поэтому сегодня это допущение используется только в частных случаях.
Наконец, мы не можем закончить разговор о работе с базами знаний, не упомянув о системах поддержки истинности (TMS, от англ. Truth Maintenance Systems).
Эти системы обеспечивают непротиворечивость баз знаний. Они особенно полезны при использовании немонотонных рассуждений, то есть методов, при которых база знаний постепенно увеличивается или уменьшается по ходу рассуждений. Системы поддержки истинности делятся на две группы: системы вертикального поиска и системы горизонтального поиска. Системы первой группы обходят базу знаний в поисках противоречий от общего к частному. При обнаружении противоречия они проходят ранее пройденный путь в обратном направлении. Системы горизонтального поиска, напротив, формулируют различные параллельные сценарии или гипотезы так, что из полученного множества контекстов по мере обнаружения противоречий последовательно исключаются отдельные варианты. Иными словами, для данного возможного контекста (представьте себе определенную позицию в шахматной партии) системы горизонтального поиска определяют сценарии, к которым можно прийти из текущей ситуации (в примере с шахматами этими сценариями будут возможные ходы), и исключают те, что оказываются противоречивыми. В шахматной партии противоречивым сценарием будет ход, при котором компьютер окажется в очень невыгодной позиции, поскольку цель компьютера — одержать победу, а неудачный ход противоречит этой цели.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Что такое уфология
Что такое уфология Уфология — увлечение, возникшее в 1950-е годы во многих странах на волне общественного интереса к НЛО. Термин «уфология» (ufology или UFOlogy) впервые появился в английском языке в 1959 г.; он происходит от аббревиатуры UFO (unidentified flying object), имеющей русский аналог —
Что такое Монголия и Татаро-Монгольское нашествие? Казаки и Золотая Орда
Что такое Монголия и Татаро-Монгольское нашествие? Казаки и Золотая Орда Задумаемся над происхождением названия «Монголия». Мы считаем, что оно произошло от слов «много», «мощь», «могл» — старорусское причастие от глагола «мочь». Отсюда произошло и греческое слово
Итак, что же такое Орда?
Итак, что же такое Орда? Орда — это, говоря современным языком, русское войско, армия. С этой точки зрения совершенно естественными становятся выражения в русских летописях вроде «князь такой?то вышел из Орды на княжение», или «князь такой-то служил царю в Орде и после
Что такое монгольский язык?
Что такое монгольский язык? Что такое монгольский язык? Огромная Монгольская империя за время своего существования, оказывается, практически не оставила после себя письменных памятников на своем «монгольском языке». Как писал профессор Казанского университета О.М.
Что такое Литва и где расположена Сибирь?
Что такое Литва и где расположена Сибирь? Источники XVI века четко отвечают на первый вопрос, вынесенный нами в заголовок. Литва — это русское государство со столицей в Смоленске. Впоследствии, когда литовский великий князь Ягайло (Яков) был избран на польский престол,
Что такое Пасхалия?
Что такое Пасхалия? Церковный календарь-пасхалия представляет собой последовательность таблиц, определяющих взаимную зависимость ряда календарных величин, многие из которых (но не все) имеют астрономический смысл, связанный со сменой лунных фаз. Вот некоторые из них:
Глава 7 Запоминающаяся глава для запоминания чисел[9]
Глава 7 Запоминающаяся глава для запоминания чисел[9] Наиболее часто мне задают вопрос о моей памяти. Нет, сразу скажу я вам, она у меня не феноменальная. Скорее, я применяю систему мнемотехники, которая может быть изучена любым человеком и описана на следующих страницах.
Глава 6
Глава 6 52. Первый вопрос. Алиса ошиблась, записав одиннадцать тысяч одиннадцать сотен и одиннадцать как 11111, что неверно! Число 11111 – это одиннадцать тысяч одна сотня и одиннадцать! Для того чтобы понять, как правильно записать делимое, сложим одиннадцать тысяч,
Глава 3
Глава 3 graphics50 14. Гусеница и Ящерка БилльГусеница убеждена в том, что и она, и Ящерка Билль оба не в своем уме. Если бы Гусеница была в своем уме, то ее суждение о том, что оба они из ума выжили, было бы ложным. Раз так, то Гусеница (будучи в своем уме) вряд ли всерьез могла быть
Глава 7
Глава 7 graphics54 64. Первый раундЕсли бы братец говорил правду, его звали бы Траляля и у него была бы карта черной масти. Но он не может говорить правду, если у него в кармане карта черной масти. Поэтому он лжет. Это означает, что у него действительно карта черной масти, а
Глава 1. Что такое анализ бесконечно малых и для чего он нужен
Глава 1. Что такое анализ бесконечно малых и для чего он нужен Анализ бесконечно малых — это область математики, которая имеет огромное значение для науки и техники. Чтобы понять, из чего состоит эта сложная и тонкая дисциплина, наверное, следует начать с рассказа о