Глава 3. Машинное обучение
Глава 3. Машинное обучение
Четверг, 6 мая 2010 года, 9:30 утра. Начинаются торги на американских фондовых биржах. Этот день ничем не отличался от остальных: утренняя сессия прошла без каких-либо аномалий. Но в 14:45 без явной причины некоторые самые важные рыночные котировки за несколько секунд обвалились. Даже с учетом высокой волатильности, характерной для финансовых рынков в период нестабильности, этот обвал был достаточно неожиданным: акции некоторых наиболее крупных и надежных компаний потеряли в цене более 60 %, а весь американский и, как следствие, мировой финансовый рынок обрушился за несколько минут. Индекс Доу-Джонса (один из наиболее популярных биржевых индексов) потерял 9,2 %, что стало крупнейшим падением в течение одного дня торгов за всю историю (этот день позже будет назван черным вторником). Позднее падение стабилизировалось, и индекс снизился «всего» на 3,2 %, но в результате за несколько секунд безвозвратно исчезли триллионы долларов.

Первые признаки обвала были обнаружены на Нью-Йоркской фондовой бирже.
Было предложено множество объяснений, но точная причина черного вторника до сих пор неизвестна. Согласно одной из гипотез, которую поддерживает большинство финансовых аналитиков, причиной обвала стала деятельность высокочастотных трейдеров (HFT — от англ. High Frequency Traders), однако рыночные регуляторы традиционно отвергали эту версию. Высокочастотные трейдеры — это автоматические интеллектуальные системы купли-продажи акций и финансовых инструментов, способные принимать решения в течение нескольких микросекунд. Сегодня системами высокочастотной торговли совершается 50 % всех международных финансовых операций.
Но как может информационная система, интеллектуальная или нет, принимать столь масштабные решения так быстро? Любой начинающий инвестор знает, что котировки ценных бумаг на финансовых рынках зависят от бесконечного множества социальных, экономических и политических факторов, начиная от последних заявлений финского министра занятости о регулировании труда в стране и заканчивая непредвиденным снижением спроса на сырье в связи с потеплением на юге Германии. Как может информационная система учитывать такой объем информации, чтобы принимать, казалось бы, интеллектуальные решения о покупке или продаже акций, причем всего за несколько секунд? Вот в чем вопрос.
Машинное обучение — один из главнейших столпов искусственного интеллекта. Мы не осознаем этого, но большинство сценариев, с которыми мы сталкиваемся каждый день, полностью контролируются мыслящими машинами. Но прежде чем начать работу, машины должны пройти обучение.
Пример обучения: диагностика опухолей
Диагностика опухолей — один из примеров, когда искусственный интеллект может оказаться крайне полезным. Прохождение маммографии с целью предотвращения рака груди является (или должно быть) регулярной практикой для взрослых женщин. Маммография — это всего лишь радиография молочных желез, позволяющая распознать аномалии, которые могут быть злокачественными опухолями. Поэтому всякий раз, когда радиолог при маммографии выявляет подобную аномалию, он проводит более подробный анализ, для которого требуется биопсия, или изъятие тканей из организма — намного более дорогостоящая и болезненная процедура, чем маммография.
Положительные результаты биопсии в 10 % случаев оказываются ложными — иными словами, при маммографии обнаруживается аномалия, однако биопсия не показывает никаких следов опухоли. Поэтому врачам крайне важно иметь в своем распоряжении средства, позволяющие свести к минимуму эти 10 % ложноположительных результатов, — чтобы снизить не только расходы на здравоохранение, но и стресс от обследования.
С другой стороны, наблюдаются и ложноотрицательные результаты, когда маммография не показывает никаких аномалий, но у пациента уже развилась опухоль. Крайне важно, чтобы новые средства диагностики позволяли снизить число как ложноположительных, так и ложноотрицательных случаев. Как вы узнаете чуть позже, снизить число ложноотрицательных случаев намного сложнее, чем ложноположительных, при этом последствия ложноотрицательных случаев намного серьезнее.
Представьте, что онколог анализирует результаты маммографии пациента, чтобы определить наличие признаков опухоли. В общем случае он выполняет следующие действия.
1. Анализ результатов маммографии и выявление наиболее важных параметров с целью определения новой проблемы. Множество выявленных параметров позволяет описать сложившуюся ситуацию.
2. Поиск иных результатов маммографии, обладающих похожими свойствами, которые были ранее получены самим врачом или приведены в специальной литературе.
3. Установление диагноза с учетом диагнозов для множества схожих результатов маммографии.
4. Наконец, при необходимости консультация с коллегами для подтверждения диагноза.
3. Запись диагноза в базу для последующего использования в будущем.
Описанная процедура полностью совпадает с одним из самых популярных методов прогнозирования, используемых в искусственном интеллекте, называется он «рассуждение по прецедентам», или CBR (от англ. Case-Based Reasoning). Рассуждение по прецедентам заключается в решении новых задач путем поиска аналогий с уже решенными задачами. После того как выбрано наиболее схожее решение, оно адаптируется к особенностям новой задачи, поэтому рассуждение по прецедентам помогает не только анализировать данные, но и достигать более общей цели — интеллектуального решения задач на основе анализа данных.
* * *
ХАРАКТЕРИСТИКИ, ИСПОЛЬЗУЕМЫЕ ПРИ ОБНАРУЖЕНИИ ОПУХОЛЕЙ ГРУДИ
Рассуждение по прецедентам, подобно другим интеллектуальным методам, может применяться для обнаружения злокачественных опухолей при маммографии. Так как входными данными в любом из подобных методов являются числа, необходим промежуточный этап, который заключается в автоматическом извлечении числовых данных из медицинских изображений. При обнаружении опухолей груди обычно производятся измерения некоторых часто встречающихся элементов молочных желез, называемых микрокальцинатами, которые представляют собой микроскопические скопления кальция в тканях. Для обнаружения злокачественных микрокальцинатов в молочных железах обычно используются следующие характеристики: площадь, периметр, компактность (соотношение между площадью и периметром), число отверстий, неровность (величина, описывающая неправильную форму микрокальцината), длина, ширина, вытянутость (соотношение между длиной и шириной) и положение центра тяжести микрокальцината.
* * *
Подобно тому как эксперт хранит накопленные знания в памяти или в блокнотах, в рассуждении по прецедентам используется структура данных под названием «память прецедентов», где хранятся ранее проанализированные случаи. Схема рассуждения по прецедентам представлена на следующем рисунке.
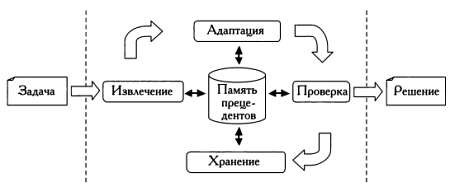
Первая фаза рассуждения по прецедентам, извлечение, состоит в поиске в памяти прецедентов решений задач, наиболее схожих с текущей. В нашем примере цель извлечения — найти прошлые результаты маммографии, по своим характеристикам схожие с полученными при обследовании.
Далее проводится адаптация — попытка адаптировать обнаруженное решение к рассматриваемому случаю. Предположим, что логистической компании необходимо перевезти груз из Лиссабона в Рим, и для оптимизации маршрута используется рассуждение по прецедентам. На первом этапе в памяти прецедентов будет произведен поиск ранее выполненных перевозок по наиболее похожим маршрутам.
Допустим, в памяти прецедентов содержится уже оптимизированный маршрут между Мадридом и Миланом. Следовательно, большая часть нового маршрута будет уже известной, и останется лишь оптимизировать путь от Лиссабона до Мадрида и от Милана до Рима. Оптимизацию этих двух небольших частей общего маршрута можно провести другими, классическими методами. Использование уже известного маршрута Мадрид — Милан при прокладке нового маршрута Лиссабон — Рим и представляет собой суть этапа адаптации.
Далее выполняется проверка, в ходе которой эксперт-человек анализирует диагноз, поставленный машиной. На этом этапе человек и машина работают вместе, что способствует непрерывному улучшению качества работы машины и повышению точности результатов. Диагностирование раковых опухолей крайне важно, поэтому руководители системы здравоохранения не передают решение этой задачи автоматическим средствам, не требующим участия человека.
На последнем этапе рассуждения по прецедентам следует определить, стоит ли включать решение, утвержденное экспертом, в память прецедентов? Иными словами, достаточно ли оно репрезентативно, чтобы включить его в набор результатов маммографии, которые будут использоваться для диагностики опухолей в будущем?
Итог рассуждений по прецедентам (и рассуждений эксперта) будет успешным только при корректном прохождении всех четырех перечисленных этапов. На каждом из этапов необходимо учитывать следующие основные аспекты.
— Критерий извлечения: не все предыдущие результаты одинаково полезны.
Следует определить, какие прецеденты нужно выбрать при рассмотрении нового случая. Для этого необходимо ввести метрики, или расстояния, позволяющие оценить схожесть нового случая и тех, что хранятся в памяти. К примеру, при анализе результатов маммографии для нового случая с помощью этих математических метрик определяется, какой из уже известных результатов больше всего схож с анализируемым.
— Критерий достоверности: для каждой предметной области характерны определенная сложность и уровень риска. В примере с диагностированием опухолей очевидно, что цена, которую необходимо заплатить в случае ложноотрицательного результата, намного выше, чем если врач посчитает доброкачественную опухоль злокачественной. Поэтому крайне важно иметь механизмы определения критериев, позволяющих гарантировать достоверность результата.
— Критерий проверки: проверка предложения требует вмешательства эксперта. В примере с анализом результатов маммографии в силу особой важности процедуры проверку производит эксперт-радиолог.
— Критерий сохранения знаний: способность решать задачи напрямую связана с имеющимся опытом их решения. Следовательно, необходимо четко обеспечить непротиворечивость знаний как при включении новых случаев, так и при устранении уже имеющихся, вносящих противоречия.
Все перечисленные выше аспекты имеют общую основу — накопленный опыт системы. Желательно, чтобы память прецедентов обладала следующими свойствами:
— компактность: память не должна содержать ни избыточных случаев, ни шума, иначе рассматриваемая ситуация будет искажена, а при подборе случаев, наиболее схожих с рассматриваемым, возникнут ошибки;
— репрезентативность: нельзя решить задачу, о которой ничего не известно, поэтому необходимо иметь репрезентативные примеры всех возможных аспектов предметной области. Только так мы гарантируем, что наше видение реальности при решении задачи будет полным;
— ограниченность: скорость работы системы напрямую зависит от того, с каким числом элементов она работает. Размер памяти определяет, способна ли система дать ответ в разумное время.
Три вышеперечисленных свойства можно свести к следующей предпосылке: необходимо располагать минимально возможным множеством независимых инцидентов, полностью описывающих предметную область.
Еще один пример: онлайн-маркетинг
С ростом популярности интернета маркетинг радикально изменился, и сегодня на смену массовому маркетингу пришел персонализированный. К примеру, когда вы открываете интернет-сайты, то видите перед собой рекламные объявления или баннеры, которые не являются ни случайными, ни статическими — напротив, различные инструменты анализируют поведение пользователя и отображают ему персонализированную рекламу в зависимости от его текущих интересов.
Каждый, кто получал электронную почту в Gmail, почтовом сервисе Google, замечал, что сбоку всегда показывается реклама, связанная с содержанием полученного письма. А если вы на прошлой неделе искали гостиницу в Париже, то не удивляйтесь, если сегодня на одной из интернет-страничек перед вами появится реклама таких гостиниц.
Все механизмы, которые использует Google и другие компании этой сферы для управления онлайн-маркетингом, представляют собой интеллектуальные инструменты, которые мгновенно и автоматически, без вмешательства человека, принимают решения о том, какую рекламу показать пользователю. Если бы в этом процессе каким-то образом участвовали люди, то выполнить в секунду десятки миллионов маркетинговых действий было бы невозможно, а речь ведь идет о цифрах именно такого порядка.
Многие считают наиболее интеллектуальным средством онлайн-маркетинга механизм предложения похожих книг, используемый компанией Amazon. Этот же механизм используют в похожих целях и другие компании, например компания Yahoo в своем Radio LAUNCHcast, где песни, положительно оцененные пользователем, фиксируются в его профиле, и в будущем система предлагает песни, которые прослушали и положительно оценили другие пользователи с похожими профилями.
Действие этой системы можно увидеть на сайте Amazon всякий раз, когда вы ищете какой-то определенный товар: независимо от того, зарегистрированы вы на сайте или нет, вы увидите раздел «Купившие этот товар также покупают» («Customers who bought this item also bought…»). Этот механизм, кажущийся тривиальным, на самом деле крайне сложен и относится к искусственному интеллекту. Он вовсе не ограничивается простым просмотром корзин покупок других пользователей, которые приобрели просматриваемый вами товар.
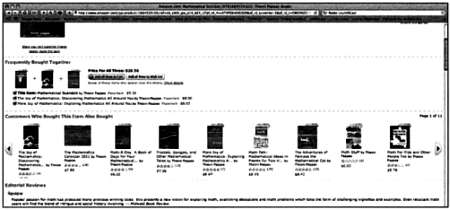
Раздел «Похожие товары» на странице интернет-магазина Amazon.
Классическое средство решения задач такого типа — так называемые байесовские сети. Крупнейший в мире научно-исследовательский институт, занимающийся изучением байесовских сетей, — это Microsoft Research Institute, где рассматриваются возможности их применения не только в онлайн-маркетинге, но и в других областях. В частности, байесовские сети применяются для автоматической адаптации интерфейса Windows в зависимости от особенностей работы и предпочтений пользователя.
Идея, на которой основаны байесовские сети, такова: существуют цепочки событий, которым с определенной вероятностью сопутствуют другие цепочки событий.
Именно поэтому байесовские сети называют сетями — они представляют собой сплетенные друг с другом цепочки вероятностных зависимостей. Рассмотрим пример с покупкой книг.

* * *
ДРУГИЕ СПОСОБЫ ИСПОЛЬЗОВАНИЯ АВТОМАТИЧЕСКОГО МАРКЕТИНГА
Автоматический маркетинг применяется не только в интернете: сегодня его используют банки, телекоммуникационные компании и даже супермаркеты. К примеру, кто не видел скидочные купоны в супермаркетах, где мы делаем покупки на неделю? Логично, что нам обычно дают купоны не на товары, которые мы и так всегда покупаем (разумеется, при условии, что скидочная программа организована правильно), а на товары, которые выбирают другие покупатели примерно с тем же набором покупок, что и мы. Таким образом мы узнаем о товарах, которые никогда раньше не покупали, и после первой покупки они могут занять постоянное место в нашей корзине. Подобным образом действуют и другие компании, в частности в сфере финансов и телекоммуникаций: с учетом нашего профиля они часто предлагают новые продукты, которые, возможно, будут нам интересны.

Супермаркет в Нью-Йорке.
* * *
В представленной сети видно, что 98 % клиентов, купивших книгу «Я, робот», также приобрели роман «Основание». И напротив, ни один из тех, кто купил «Дюну», не приобрел «Гордость и предубеждение», поэтому между этими двумя книгами не существует никакой связи. Если система обнаруживает, что клиент недавно купил книгу «Я, робот» и теперь ищет информацию о книге «Основание», в разделе рекомендаций он увидит «Дюну» и «Контакт», так как их приобрела значительная доля покупателей, купивших первые две книги. Все вышеперечисленные действия образуют индивидуальную маркетинговую кампанию для каждого клиента, цель которой — повышение продаж. В ходе этих кампаний покупателям автоматически предлагаются два товара, о существовании которых они, возможно, и не подозревали. Система располагает обширной информацией о прошлых покупках и формирует представленную выше сеть причинно-следственных связей для рекомендации новых товаров.
Системе также известно, что рекламировать «Гордость и предубеждение» тому,
кто покупает научно-фантастические романы (а именно это происходит при классических маркетинговых кампаниях), — пустая трата времени. В рамках традиционной маркетинговой кампании выход нового издания «Гордости и предубеждения» мог быть объявлен, к примеру, в тематической программе о книгах, выходящей в эфир в 23:00 на канале, посвященном культуре. Но даже если бы маркетологи верно выбрали программу и время ее выхода в эфир так, чтобы ее с большой вероятностью посмотрели люди, заинтересованные в продукте, на многих любителей научной фантастики реклама не произвела бы никакого эффекта. При использовании статического канала маркетинга, например телевидения, радио или афиш на улицах, рекламодатель не может определить индивидуальный профиль клиента. И даже если профиль клиента известен, рекламодатель не располагает необходимыми средствами для того, чтобы адаптировать рекламу для каждого из нас.
Мозг робота: нейронные сети
Робототехника — одна из самых сложных областей инженерии, и не только потому, что в простой руке робота используется множество сервоприводов и электронных устройств. Ее сложность связана с тем, что траектории движения подвижных частей робота определяются путем сложных математических расчетов. В некоторых случаях все расчеты выполняются в искусственном мозге робота, состоящем, подобно мозгу высших живых организмов, из нейронных сетей. Но в случае с роботами речь идет об искусственных нейронах.
Схематичное изображение нейрона человеческого мозга.
Понятия «нейронная сеть» и «искусственный нейрон» появились не так давно, и эйфория по отношению к ним уже не раз сменялась разочарованием. Эти понятия возникли как составляющие алгоритма Threshold Logic Unit (блок пороговой логики), который был предложен Уорреном Маккалоком и Уолтером Питтсом в 1940-е годы и имел большой успех. Искусственный нейрон, по сути, представляет собой инкапсуляцию указанного алгоритма. Специалисты описывают искусственный нейрон следующим образом:
Вход1 —> X1
Вход2 —> Х2
…
Входi —> Xi
Если
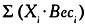 > Пороговое значение,
> Пороговое значение,
то Выход <— 1
иначе Выход <— 0
На обычном языке это означает: нейрон возбуждается тогда и только тогда, когда стимул, то есть сумма произведений (Xi?Весi), превышает определенное пороговое значение.
Как вы можете видеть, нейрон крайне прост, поскольку требует лишь нескольких арифметических действий и одну операцию сравнения. Простота искусственных нейронов способствовала их реализации в микрочипах. К концу 90-х годов стала возможной полная реализация искусственных нейронных сетей исключительно в аппаратном обеспечении. Сегодня эти микрочипы используются при изготовлении электронных прогнозных устройств, к примеру, приборов, позволяющих определить причину недомогания плачущего ребенка.
Искусственный нейрон функционирует аналогично естественному. Но основная сложность нейронных сетей заключается в двух элементах, которые должны согласовываться между собой. Именно от них зависит, сможет ли нейронная сеть делать более или менее точные прогнозы. Эти два элемента — вес входных сигналов и пороговое значение. Трудоемкая корректировка этих значений, по результатам которой для ряда входных значений нейрон должен выдавать желаемое выходное значение, называется обучением. Прорыв в обучении нейронов совершил Фрэнк Розенблатт в конце 1950-х, предложив модель нейрона, способного корректировать веса и пороговое значение. Модель Розенблатта получила название перцептрон.
С точки зрения биологии реальный нейрон ведет себя почти так же: каждый нейрон имеет множество входов, куда поступают электрические сигналы от других нейронов (соединения между нейронами называются синапсами), затем определяется, превышают ли эти стимулы порог чувствительности. При этом следует учитывать, что некоторые синапсы важнее других (важность синапсов описывается с помощью весов, о которых мы упоминали выше). Если порог чувствительности превышен, то по аксону проходит электрический сигнал (в случае с искусственным нейроном аналогом этого сигнала будет выходное значение).
Перцептрон оказался полезным при прогнозировании: он способен предсказать, к какому классу принадлежит заданная выборка. Классическим примером является задача о растениях рода ирис, в которой рассматриваются выборки трех видов: ирис щетинистый (Iris setosa), ирис разноцветный (Iris versicolor) и ирис виргинский (Iris virginica). Каждая выборка описывается четырьмя параметрами: длиной и шириной лепестков, длиной и шириной чашелистиков. Цель задачи — определить, к какому виду принадлежат растения из новой выборки. Для решения будем использовать три перцептрона, каждый из которых настроен на обнаружение одного из трех видов. Таким образом, если новая выборка содержит растения вида ирис щетинистый, то всего один перцептрон вернет значение 1, два других — 0.

По порядку: ирис щетинистый, ирис разноцветный и ирис виргинский.
В зависимости от формы и размеров лепестков и чашелистиков система способна определить, к какому виду принадлежат цветы.
Читатель, возможно, задается вопросом: почему для решения задачи об ирисах нельзя использовать методы статистики? И действительно, эта задача так проста, что ее можно решить классическими методами статистики, к примеру, методом главных компонент. Но обратите внимание, что перцептрон и статистические методы описывают две принципиально различные схемы рассуждений, и описанная перцептроном, возможно, точнее соответствует естественным рассуждениям.
При решении задачи об ирисах методами статистики мы получили бы правила вида «если длина лепестков находится на интервале между указанными значениями, а ширина — между другими указанными значениями, весьма вероятно, что выборка принадлежит к виду Х». Перцептрон же рассуждает следующим образом: «если длина лепестков находится на интервале между указанными значениями, а ширина — между другими указанными значениями, весьма вероятно, что выборка принадлежит к виду X. Но если чашелистики слишком коротки, то размеры лепестков уже не имеют значения, так как выборка будет принадлежать к виду У».
Иными словами, при взвешивании входных значений для принятия решений одни данные могут иметь больший вес, чем другие, однако при достижении предельных значений входные данные, ранее считавшиеся неважными, начинают играть важную роль.
Нейроны группируются…
Несмотря на прорыв, которым стало открытие перцептрона и грандиозные перспективы его применения, ученые вскоре обнаружили: перцептроны нельзя использовать для решения линейно неразделимых задач (к несчастью, именно к этой группе относится большинство задач реальной жизни). По этой причине в 1980-е годы в адрес нейронных сетей прозвучало немало критики, а участники дебатов порой переходили от научных рассуждений к личным оскорблениям оппонентов.
К великому разочарованию ученых, эти споры пришлись на «темные века» в истории искусственного интеллекта — период, отмеченный существенным снижением выделяемых средств на исследования в США и Европе.
Во-первых, общество поняло, что идеи, изображенные в «Космической одиссее 2001 года», еще долго не найдут воплощения. Во-вторых, американские государственные организации, которые возлагали большие надежды на искусственный интеллект, считая, что он поможет одержать верх в холодной войне, постигла неудача. Разочарование ждало и тех, кто связывал свои ожидания с системами автоматического перевода, крайне важными для изучения советских технических документов. Когда стала понятна неэффективность перцептронов для решения линейно неразделимых задач, финансирование исследований в этой области существенно снизилось. Однако ученые продолжили исследования, хотя и опасаясь насмешек со стороны недоброжелателей.

В течение многих лет считалось, что создание сверхразумных компьютеров, подобных HAL 9000 из фильма «Космическая одиссея 2001 года», более чем реально. Увы, вскоре наступило разочарование.
* * *
ЛИНЕЙНАЯ НЕРАЗДЕЛИМОСТЬ
Рассмотрим ситуацию, когда выборки могут принадлежать к одной из двух категорий, каждая из которых описывается двумя дескрипторами (следовательно, двумя входными значениями).
Нарисуем график для восьми выборок.
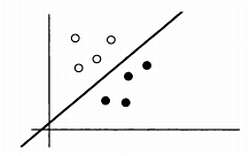
На этом графике кругами белого цвета отмечены выборки категории А, черными — выборки категории В. Нетрудно провести линию, разделяющую категории, — именно эту операцию проводит перцептрон при корректировке порогового значения и весов входных значений. Но что произойдет, если мы рассмотрим синтетическую задачу, предметом которой является операция XOR? XOR — это логическая операция, соответствующая исключающему «или», которая описывается следующим соотношением:
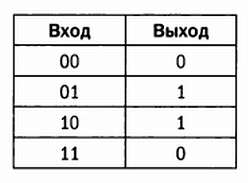
Теперь график будет выглядеть так:
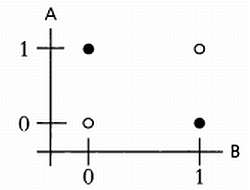
Теперь уже нельзя провести линию, отделяющую белые круги от черных, следовательно, эта задача является линейно неразделимой. Перцептрон нельзя корректно обучить для решения такой простой логической задачи, как задача XOR.
* * *
Решение проблемы линейной неразделимости было найдено в конце 80-х годов.
Оно было столь очевидным и естественным, что даже странно, почему никто не додумался до него раньше. Решение нашла сама природа еще несколько миллионов лет назад: достаточно связать между собой различные перцептроны, сформировав так называемую нейронную сеть.
На следующем рисунке изображена нейронная сеть, состоящая из трех слоев нейронов: первый слой — входной, второй — скрытый, третий и последний — выходной. Эта нейронная сеть называется сетью прямого распространения, так как поток данных в ней всегда направлен слева направо, а синапсы не образуют циклов.
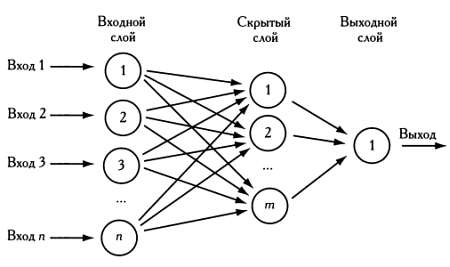
Нейронная сеть может быть сколь угодно сложной, иметь произвольное число скрытых слоев и, кроме того, содержать связи, которые идут в обратном направлении и тем самым моделируют некую разновидность памяти. Ученые построили нейронные сети, содержащие до 300 тысяч нейронов — столько, сколько содержит нервная система земляного червя.
В нейронной сети процесс обучения усложняется, поэтому инженеры разработали множество методов обучения. Один из самых простых — метод обратного распространения ошибки, давший название отдельной разновидности нейронных сетей, в которой он используется. Суть этого метода состоит в снижении ошибки выходного значения нейронной сети путем корректировки весов входных значений синапсов в направлении справа налево по методу градиентного спуска. Иными словами, сначала весам всех синапсов нейронной сети присваиваются произвольные значения, после чего на вход сети подается выборка, выходное значение для которой известно (такая выборка называется обучающей). Как и следовало ожидать, в этом случае выходное значение будет случайным. Далее, начиная с нейронов, близких к выходу, и заканчивая нейронами входного слоя, начинается корректировка весов связей.
Цель этой корректировки — приблизить выходное значение нейронной сети к реальному известному значению.
Эта процедура повторяется несколько сотен или тысяч раз для всех обучающих выборок. Когда обучение для всех выборок завершено, говорят, что прошла эпоха обучения. Далее процесс обучения может быть повторен на протяжении еще одной эпохи для тех же обучающих выборок. Как правило, при обучении рассматривается несколько десятков выборок. Этот процесс подобен реальному обучению, когда человек вновь и вновь видит одни и те же данные.
* * *
ОПАСНОСТЬ ПЕРЕОБУЧЕНИЯ
Система прогнозирования, в которой применяется машинное обучение, формулирует прогнозы путем обобщения предшествующего опыта. Следовательно, система, неспособная совершать обобщения, становится бесполезной.
Если процесс обучения повторяется слишком много раз, наступает момент, когда веса подобраны столь точно и система настолько адаптировалась к обучающим выборкам, что прогнозы формулируются не путем обобщения, а на основе запомненных случаев. Система становится способной выдавать корректные прогнозы для обучающих выборок, но всякий раз, когда на вход будет подаваться иная выборка, полученный прогноз окажется некорректным. Такая ситуация называется переобучением.
Нечто похожее происходит с ребенком, который не учится умножать, а запоминает таблицу умножения. Если мы попросим его найти произведение двух чисел из таблицы, он ответит без запинки, но если мы попросим его перемножить два других числа, ребенок задумается.
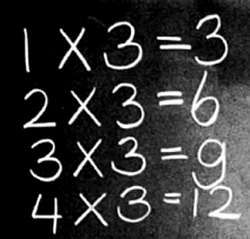
Таблицы умножения — прекрасный пример обучения путем запоминания.
* * *
С годами архитектура нейронных сетей и методы обучения усложнялись. Постепенно возникло множество разновидностей нейронных сетей для решения самых разных задач реальной жизни. Сегодня наиболее часто используются нейронные сети Хопфилда, в которых реализован механизм запоминания под названием «ассоциативная память».
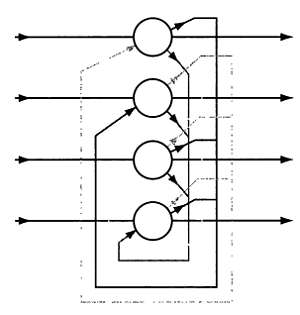
Схема нейронной сети Хопфилда.
В ассоциативной памяти информация упорядочена по содержанию. Следовательно, для доступа к ней необходимо указать содержание информации, а не ее физическое расположение, как при чтении с жесткого диска или из оперативной памяти компьютера.
Другой тип нейронных сетей, широко используемых сегодня, это самоорганизующиеся карты Кохонена. Нейронные сети этого типа содержат новаторское решение: их обучение происходит не под наблюдением. Напротив, сама сеть учится на своих ошибках.
…и мозг начинает работать
В физике существует отдельная дисциплина, инверсная кинематика, которая занимается расчетом движений, необходимых для того, чтобы переместить предмет из точки А в точку В. По мере внесения в систему новых степеней свободы сложность расчетов (различных операций над матрицами) возрастает экспоненциально.
Рассмотрим в качестве примера роботизированную руку с выдвижным манипулятором, способную вращаться в четырех местах. Если мы будем решать матричные уравнения инверсной кинематики классическим способом, то даже суперкомпьютеру потребуется несколько часов на то, чтобы определить, как именно необходимо сместить руку в каждом направлении, чтобы переместить инструмент, закрепленный в манипуляторе, из точки А в точку В.
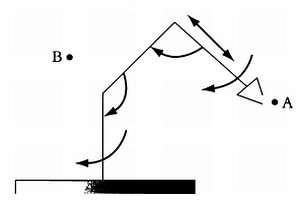
Таким образом, при реализации роботизированных систем, способных изменять траектории движения в реальном времени, классические методы решения матричных уравнений неприменимы. Если речь идет о роботах, систематически выполняющих одни и те же задачи (это могут быть роботы на сборочном конвейере автомобильного завода), то можно заранее рассчитать и последовательно запрограммировать работу моторов и выдвижного манипулятора. Но если мы хотим сконструировать роботизированную руку, способную действовать автономно и координировать движения в зависимости от ситуации (представьте себе роботов, которые используются на космических кораблях, в хирургии или первых экспериментальных домашних роботов), то нам потребуются более передовые системы, способные быстро вычислять, как именно должны двигаться детали робота, чтобы выполнить поставленную задачу.
На сегодняшний день при создании роботов такого типа эффективно используются нейронные сети с обратным распространением ошибки. В нашем примере нейронная сеть, обученная управлять движениями робота, будет иметь столько выходных нейронов, сколько роботу доступно степеней свободы. Каждый выходной нейрон указывает, на сколько нужно сместиться в каждом направлении, чтобы переместиться из начальной точки в конечную.
Значительное неудобство этого метода по сравнению с классическими подходами состоит в том, что нейронная сеть должна пройти длительное обучение, сравнимое с обучением человека, который в детстве учится ходить. Для человека, уже овладевшего этим навыком, не представляет трудности решать на каждом шаге сложные физические уравнения кинематики и переставлять ноги, не теряя равновесия.
При классическом обучении нейронных сетей с обратным распространением ошибки вновь и вновь рассматриваются десятки тысяч примеров и сотни тысяч возможных траекторий. И для каждой из рассматриваемых траекторий нейронная сеть обучается приводить в действие различные моторы, чтобы робот переместился из начальной точки в конечную.
После завершения обучения нейронной сети говорят, что она усвоила сенсомоторную карту. В результате центр управления роботом может с высочайшей точностью решать задачи инверсной кинематики всего за несколько миллисекунд.
Мозг усложняется
Успехи в использовании нейронных сетей привели к тому, что уже в XXI веке они стали стандартным инструментом решения множества задач. Однако нейронные сети обладают серьезными недостатками.
Первый из них — переобучение. Второй — большое число параметров, значения которых следует задавать вручную, случайным образом, до начала обучения нейронной сети. Здесь основная проблема заключается в том, что не существует каких-либо руководств и методик, описывающих, как именно следует задавать значения параметров. В результате на решение этой задачи приходится тратить значительные человеческие и технические ресурсы и в большинстве случаев прибегать к старому проверенному методу проб и ошибок. Третий недостаток, носящий скорее философский, нежели практический характер, заключается в том, что мы не понимаем, как именно рассуждает обученная нейронная сеть. Этому не придавалось особого значения до тех пор, пока нейронные сети не стали в полной мере применяться для решения реальных задач. Если мы, к примеру, используем нейронную сеть для контроля антиблокировочной системы автомобиля (ABS), то вполне логично, что инженеры хотят до мельчайших подробностей понимать, как рассуждает нейронная сеть, — только так они могут быть уверены, что тормоза не откажут ни в одной из многих тысяч возможных ситуаций.

Нейронная сеть формулирует прогнозы, однако неизвестно, как именно она при этом рассуждает. Некоторые сравнивают нейронные сети с магическим кристаллом.
С конца 90-х годов многие специалисты по теории вычислений интенсивно работают над созданием новых вычислительных методов, которые позволят устранить эти недостатки или хотя бы снизить их негативный эффект. Окончательное решение в начале XXI века предложила группа под руководством Владимира Вапника из знаменитой компании AT&T Bell Labs, специализирующейся на телекоммуникациях и производстве электроники. Вапник разработал метод опорных векторов (англ. SVM — Support Vector Machine), при котором для решения линейно неразделимых задач вводятся новые, искусственные измерения, позволяющие преобразовать исходную задачу в линейно разделимую.
Метод опорных векторов лишен большинства недостатков нейронных сетей, поэтому сегодня он пришел им на смену практически во всех областях компьютерных технологий. Тем не менее нейронные сети до сих пор используются в промышленности, в частности в робототехнике, благодаря простой аппаратной реализации.
Нужны ли экзамены?
Как вы уже знаете, машинное обучение может применяться во всех областях науки и техники. Но можно ли пойти дальше и применить его в образовании? Как преподаватель определяет уровень знаний учеников? Можно ли автоматизировать некоторые субъективные критерии, которые используют школьные учителя и университетские преподаватели для оценки знаний учащихся? Можно ли спрогнозировать уровень знаний ученика, не проводя экзаменов? На все эти вопросы поможет ответить дерево принятия решений.

Исчезнет ли подобная картина в будущем? Этого наверняка хотят многие студенты.
Деревья принятия решений крайне просты, но очень эффективны для распознавания образов. Они позволяют выяснить, какие переменные играют определяющее значение при отнесении выборки к тому или иному классу. Рассмотрим пример. Допустим, что мы хотим спрогнозировать оценки студентов и располагаем следующими исходными данными.
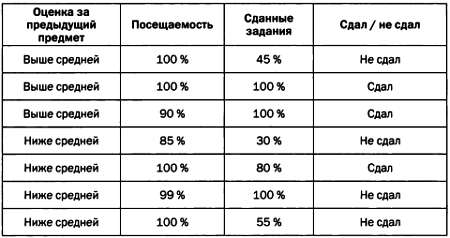
Хорошее дерево принятия решений, составленное с учетом этих данных, может выглядеть следующим образом.
* * *
ИНФОРМАЦИОННОЕ ДЕРЕВО
Дерево — это структура данных, которая очень широко используется в инженерном деле, так как позволяет строить иерархии данных. При работе с деревьями используются особые понятия.
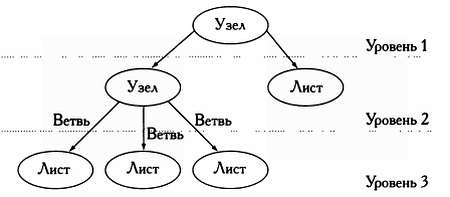
Данные, представленные в дереве, называются узлами. Эти узлы, представляющие единицы информации, делятся на разные уровни и связываются между собой ветвями. Узел, связанный с узлом более высокого уровня, называется потомком, узел, связанный с узлом низшего уровня, — родителем. Узлы, не имеющие потомков, называются листьями.
* * *
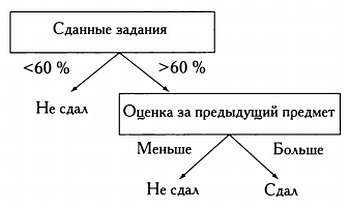
В этом случае посещаемость не является определяющей переменной, поэтому не представлена в виде узла дерева. Существуют различные методологии, позволяющие определить, является ли переменная модели дискриминантной (иными словами, можно ли разделить выборку на группы в зависимости от значений этой переменной). В основе одной из самых популярных методологий лежит понятие энтропии Шеннона. В рамках этой методологии для каждого уровня дерева определяется переменная, порождающая меньше всего энтропии. Именно эта переменная и будет дискриминантной для рассматриваемого уровня. Рассмотрим метод подробнее.
Энтропия Шеннона S рассчитывается по следующей формуле:
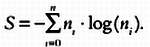
Попробуем применить это понятие в нашей задаче об экзаменах. На первом уровне дерева необходимо проанализировать энтропию, порождаемую каждой переменной. Первая переменная — «оценка за предыдущий предмет». Если мы разделим выборки в зависимости от значений этой переменной, получим два подмножества выборок. Для первого подмножества энтропия Шеннона будет равна
SОценка за предыдущий предмет ниже средней = -0,75?log(0,75) — 0,25?log(0,25) = 0,56,
так как среди студентов, которые в прошлом году получили оценку ниже средней, не сдали экзамен 75 %, сдали — 25 %. Для второго множества энтропия Шеннона будет равна
SОценка за предыдущий предмет ниже средней = -0,33?log(0,33) — 0,67?log(0,67) = 0,64,
так как треть студентов, которые в прошлом году получили оценку выше средней, не сдали экзамен, две трети студентов — сдали.
Подобные расчеты повторяются для каждой переменной. Следующая переменная — «посещаемость». Для простоты установим граничное значение посещаемости, равное 95 %. В этом случае
SПосещаемость выше 95 % = -0,6?log (0,6) — 0,4?log(0,4) = 0,67;
SПосещаемость выше 95 % = -0,5?log (0,5) — 0,5?log(0,5) = 0,69
Наконец, рассмотрим переменную «сданные задания» и вновь для простоты разобъем выборку на 2 группы, выделив тех, кто сдал больше и меньше 60 % заданий.
Имеем:
SСдано более 60 % заданий = -0,75?log(0,75) — 0,25?log(0,25) = 0,56;
и
SСдано более 60 % заданий = -1?log(1) = 0
Следовательно, наилучшей дискриминантной переменной будет последняя, так как энтропия подмножеств, выделенных на ее основе, равна 0,56 и 0.
В этом случае все представители обучающей выборки, сдавшие менее 60 % заданий, не сдали экзамен, следовательно, эту ветвь дерева можно не рассматривать.
Но другая ветвь содержит одинаковое число студентов, сдавших и не сдавших экзамен. Следовательно, необходимо продолжить анализ, не учитывая уже дискриминированные выборки.
Теперь остались только две переменные, которые могут повлиять на итоговое решение: «оценка за предыдущий предмет» и «посещаемость». Значения энтропии Шеннона для групп, выделенных в зависимости от значений первой дискриминантной переменной, таковы:
SОценка за предыдущий предмет ниже средней = -0,5?log (0,5) — 0,5?log (0,5) = 0,69;
SОценка за предыдущий предмет ниже средней = -1?log(1) = 0
Если мы рассмотрим переменную «посещаемость»,
SПосещаемость выше 95 % = -0,33?log (0,33) — 0,67?log (0,67) = 0,64;
SПосещаемость выше 95 % = -1?log(1) = 0
В качестве дискриминантной переменной мы выберем «посещаемость», так как для нее характерна меньшая энтропия.
Метод построения деревьев принятия решений и, следовательно, метод обучения деревьев прост и элегантен, однако обладает двумя значительными недостатками.
Первый из них состоит в том, что задачи с большим числом переменных решаются очень медленно. Второй, более серьезный, заключается в том, что результатом работы алгоритма будет не глобальный, а локальный оптимум. Иными словами, так как дерево всегда анализируется не полностью, а по отдельным уровням, возможно, что на каком-то этапе определенная переменная будет выбрана потому, что она снижает энтропию на своем уровне, однако при выборе другой переменной общее решение будет более оптимальным.
Чтобы повысить качество решений, получаемых с помощью деревьев, часто используются так называемые леса: с помощью различных методов производится обучение нескольких деревьев, а итоговый прогноз формируется с учетом результатов, полученных для каждого дерева..
В рамках этого подхода при обучении леса деревья принятия решений чаще всего строятся путем случайного выбора переменных. Иными словами, если мы хотим обучить 100 деревьев, составляющих лес, то для каждого дерева выберем пять случайных переменных и произведем обучение только с этими пятью переменными. Этот приближенный метод носит поэтическое название random forest («случайный лес»).
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Глава 7 Запоминающаяся глава для запоминания чисел[9]
Глава 7 Запоминающаяся глава для запоминания чисел[9] Наиболее часто мне задают вопрос о моей памяти. Нет, сразу скажу я вам, она у меня не феноменальная. Скорее, я применяю систему мнемотехники, которая может быть изучена любым человеком и описана на следующих страницах.
Глава 1
Глава 1 Кто Джон? Для того чтобы узнать, кого из двух братьев-близнецов зовут Джон, нужно спросить одного из них: «Джон говорит правду?». Если в ответ на этот вопрос последует «да», то независимо от того, лжет ли спрошенный близнец или говорит всегда только правду, он должен
Глава 2
Глава 2 1. История первая. По существу, Болванщик заявил, что варенье украли либо Мартовский Заяц, либо Соня. Если Болванщик солгал, то ни Мартовский Заяц, ни Соня не украли варенье. Но тогда Мартовский Заяц, поскольку он не украл варенье, дал правдивые показания.
Глава 5
Глава 5 42. Появление первого шпиона. С заведомо не может быть рыцарем, так как ни один рыцарь не стал бы лгать и утверждать, будто он шпион. Следовательно, С либо лжец, либо шпион. Предположим, что С шпион. Тогда показание А ложно, значит, А шпион (А не может быть шпионом, так
Глава 6
Глава 6 52. Первый вопрос. Алиса ошиблась, записав одиннадцать тысяч одиннадцать сотен и одиннадцать как 11111, что неверно! Число 11111 – это одиннадцать тысяч одна сотня и одиннадцать! Для того чтобы понять, как правильно записать делимое, сложим одиннадцать тысяч,
Глава 7
Глава 7 64. Первый раунд (Красное н черное). Если внезапно заговоривший братец сказал правду, то его звали бы Траляля и в кармане у него была бы черная карта. Но тот, у кого в кармане карта черной масти, не может говорить правду. Следовательно, он лжет. Значит, в кармане у него
Глава 9
Глава 9 Во всех решениях этой главы А означает первого подсудимого, В – второго и С – третьего.78. Кто виновен? Из условий задачи известно, что виновный дал ложные показания. Если бы В был виновен, то он сказал бы правду, когда признал виновным себя. Следовательно, В не может
Глава 11
Глава 11 88. Всего лишь один вопрос. Действительно следуют. Рассмотрим сначала утверждение 1. Предположим, некто убежден, что он бодрствует. В действительности он либо бодрствует, либо не бодрствует. Предположим, что он бодрствует. Тогда его убеждение правильно, но всякий,
Глава 1
Глава 1 graphics46 Кто Джон?Чтобы узнать, кто из двух братьев Джон, спросите одного из них: «Джон правдив?» Если он ответит «да», это должен быть Джон, независимо от того, солгал он или сказал правду. Если же он ответит «нет», значит, он не Джон. И вот как это подтверждается.Ответив
Глава 2
Глава 2 graphics48 1. История перваяШляпник заявил, по существу, что повидло украл либо Мартовский Заяц, либо Соня. Если Шляпник солгал, значит ни Мартовский Заяц, ни Соня повидла не крали. Раз Мартовский Заяц кражи не совершал, то он, следовательно, сказал на суде правду.
Глава 3
Глава 3 graphics50 14. Гусеница и Ящерка БилльГусеница убеждена в том, что и она, и Ящерка Билль оба не в своем уме. Если бы Гусеница была в своем уме, то ее суждение о том, что оба они из ума выжили, было бы ложным. Раз так, то Гусеница (будучи в своем уме) вряд ли всерьез могла быть
Глава 5
Глава 5 graphics51 42. Разоблачение Первого ШпионаВ определено не может быть рыцарем, поскольку ни один рыцарь не мог бы оболгать самого себя, назвавшись шпионом. Следовательно, В либо жулик, либо шпион. Предположим, В — шпион. Тогда заявление А ложно и в этом случае А — жулик (он
Глава 7
Глава 7 graphics54 64. Первый раундЕсли бы братец говорил правду, его звали бы Траляля и у него была бы карта черной масти. Но он не может говорить правду, если у него в кармане карта черной масти. Поэтому он лжет. Это означает, что у него действительно карта черной масти, а
Глава 9
Глава 9 Для всех решений в этой главе назовем первого подсудимого А, второго — Б и третьего — В. graphics56 78. Кто виновен?Нам дано, что солгал тот, кто был виновен. Если бы это был Б, он сказал бы правду, признав свою вину, поэтому Б не может быть виновным. Если бы виновным был А, то
Глава 11
Глава 11 88. ВопросДа, эти утверждения действительно следуют из теории Черного Короля. Начнем с Утверждения 1. Предположим, некто считает, что он бодрствует. Он либо на самом деле бодрствует, либо спит. Предположим, он на самом деле бодрствует. Тогда его суждение верно, но