Глава 5. Анализ данных
Глава 5. Анализ данных
Руководство крупной американской сети супермаркетов Osco несколько лет назад поставило перед службой информационных технологий задачу разработать систему, способную анализировать огромные объемы данных, генерируемых ежедневно.
Предполагалось, что в результате анализа станут понятны рыночные тенденции.
Сразу после заверения работы над системой была обнаружена удивительная тенденция: в период с 17:00 до 19:00 существенно возрастали совокупные продажи подгузников и пива. Иными словами, масса клиентов, приобретавших в это время подгузники, включали в свою продуктовую корзину и пиво. Эта тенденция сначала обеспокоила исследователей, однако вскоре нашлось и объяснение: клиенты с маленькими детьми не могут отправиться на футбол, баскетбол или бейсбол, поэтому они покупали пиво, чтобы пить его во время телевизионной трансляции матчей.
Как компания Osco использовала эту информацию? Полки с подгузниками и пивом были переставлены ближе друг к другу, и совокупные продажи обеих групп товаров значительно возросли. Этот пример использования информационных систем получил известность, и сегодня все крупные торговые сети используют хранилища данных и средства интеллектуального анализа для изучения тенденций рынка и запуска новых продуктов.
О том, что такое интеллектуальный анализ данных и хранилище данных, мы расскажем чуть позже. Пока лишь отметим, что анализ данных — это дисциплина, в которой изучаются способы извлечения информации из систематически собираемых сведений. В силу растущей сложности данных среды проводить подобный анализ с каждым разом становится все труднее, и сегодня интеллектуальный анализ данных выделяют в отдельную дисциплину на стыке искусственного интеллекта и статистики.
Анализ данных возник в XVIII веке одновременно с появлением первых современных государств, осуществлявших систематический сбор информации о населении и состоянии экономики. Интеллектуальный анализ данных появился значительно позже, в конце XX века, когда вычислительные мощности и новые методы искусственного интеллекта достигли уровня, достаточного для того, чтобы извлекать информацию из огромных объемов данных.
Интеллектуальный анализ данных
Результатом классического интеллектуального анализа данных является математическая модель, которая помогает объяснить выявленные в ходе анализа тенденции.
Также эта модель позволяет предсказать появление новых тенденций и даже провести классификацию или сегментирование данных на основе шаблонов поведения, выявить которые совсем не просто.

При интеллектуальном анализе результатом обработки данных является информация, из которой извлекаются знания.
Фундаментальные средства анализа данных основывались на понятиях, связанных с условной вероятностью и предложенных священником Томасом Байесом еще в XVIII веке. Проблема, которая серьезно осложняет анализ данных, заключается в том, откуда берутся сами данные. К примеру, представим, что мы хотим проанализировать сведения о пациентах, страдающих от раковых заболеваний, и обращаемся к архиву онко диспансера. Как правило, в подобных архивах содержится намного больше информации о больных пациентах, чем о здоровых, ведь источником данных является больница. Это исходное отклонение Байес выразил с помощью введенного им понятия условной вероятности, которое мы уже объясняли в предыдущей главе.
Результатом исследований условной вероятности Байеса стал ряд методов, позволяющих учесть это исходное отклонение и сделать точные выводы. В общем случае интеллектуальный анализ данных делится на следующие этапы.
1. Отбор множества данных. На этом этапе выбираются целевые переменные, на основе которых будут производиться сегментирование, классификация или прогнозирование, а также независимые переменные — данные, на основе которых будут строиться модели. Часто обработать все доступные данные невозможно, поэтому на этапе отбора необходимо произвести выборку данных для анализа.
2. Анализ особенностей данных. На этом этапе проводится первое простое изучение данных для выявления нетипичных значений, выходящих за разумные пределы. Также определяются переменные, которые не предоставляют важной информации для решения задачи.
3. Преобразование входных данных. На этом этапе обычно проводится нормализация данных, чтобы избежать серьезных ошибок на последующих этапах моделирования. Предположим, что в задаче рассматриваются две переменные — рост и вес жителей страны. Рост, скорее всего, будет указываться в сантиметрах или даже миллиметрах, вес — в килограммах. Если мы будем использовать нейронную сеть для моделирования этих данных, то получим некорректные результаты из-за больших различий во входных значениях (рост человека может достигать двух тысяч миллиметров, а вес редко превышает сто килограммов). Поэтому данные обычно преобразуются так, чтобы минимальное значение равнялось 0, максимальное — 1.
4. Моделирование. Это основной этап интеллектуального анализа данных. Методы анализа данных делятся на группы в зависимости от того, какие приемы используются на этом этапе. По этой причине моделирование обычно охватывает ряд средств и методологий, как правило, относящихся к мягким вычислениям (эта дисциплина изучает методы решения задач с неполными или неточными данными) и неизменно направленных на извлечение нетривиальной информации. Сюда относятся нейронные сети, метод опорных векторов и так далее.
5. Извлечение знаний. Часто на предыдущем этапе не удается мгновенно извлечь знания из данных. На этом этапе применяются различные инструменты, к примеру, позволяющие получить новые знания при помощи корректно обученной нейронной сети.
6. Интерпретация и оценка данных. Несмотря на интенсивное использование компьютерных методов в интеллектуальном анализе данных, этот процесс по прежнему далек от полной автоматизации. Значительная часть интеллектуального анализа данных выполняется вручную, а качество результатов зависит от опыта инженера. По этой причине после завершения процесса извлечения знаний необходимо проверить корректность выводов, а также убедиться, что они нетривиальны (к примеру, тривиальным будет знание о том, что рост всех людей заключен на интервале от 1,4 до 2,4 м). Также при реальном интеллектуальном анализе одни и те же данные анализируются при помощи разных методологий. На этом этапе производится сравнение результатов, полученных с помощью различных методов анализа и извлечения знаний.
* * *
ПАПА РИМСКИЙ — ПРИШЕЛЕЦ?
В 1996 году Ханс-Петер Бек-Борнхольдт и Ханс-Херманн Даббен в статье, опубликованной в престижном журнале Nature, рассмотрели вопрос: действительно ли Папа Римский — человек? Они рассуждали следующим образом: если мы выберем одного человека случайным образом, то вероятность того, что он будет Папой Римским, составит 1 к 6 миллиардам. Продолжим силлогизм: вероятность того, что Папа Римский — человек, равна 1 к 6 миллиардам.
Опровержение этих рассуждений привели Шон Эдди и Дэвид Маккей в том же самом журнале, применив условную вероятность. Они рассуждали следующим образом: вероятность того, что некий человек — Папа Римский, вовсе не обязательно равна вероятности того, что некий индивид — человек, если он — Папа Римский. Применив математическую нотацию, имеем:
Р(человек | Папа Римский) =/= р(Папа Римский | человек).
Если мы хотим узнать значение Р (человек | Папа Римский), нужно применить теорему Байеса. Получим:
Допустим, вероятность того, что некий индивид (житель планеты Земля) — пришелец, пренебрежимо мала
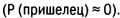 ). Тогда вероятность того, что этот индивид — человек, стремится к 1
). Тогда вероятность того, что этот индивид — человек, стремится к 1
 . Вероятность того, что пришелец будет избран Папой Римским, еще меньше (Р (Папа Римский | пришелец) < 0,001). Следовательно, можно со всей уверенностью утверждать, что
. Вероятность того, что пришелец будет избран Папой Римским, еще меньше (Р (Папа Римский | пришелец) < 0,001). Следовательно, можно со всей уверенностью утверждать, что
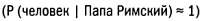
Проклятие размерности
Прекрасно известно, что интуиция, не подкрепленная размышлениями, — злейший враг статистики и теории вероятностей. Многие думают, что при анализе данных большой объем входных данных (но не выборок) позволит получить больше информации, а следовательно, и больше знаний. С этим заблуждением традиционно сталкиваются начинающие специалисты по интеллектуальному анализу данных, и распространено оно настолько широко, что специалисты называют его проклятием размерности.
Суть проблемы заключается в том, что при добавлении к математическому пространству дополнительных измерений его объем возрастает экспоненциально.
К примеру, 100 точек (102) — достаточная выборка для единичного интервала, при условии, что расстояние между точками не превышает 0,01. Но в кубе единичной стороны аналогичная выборка должна содержать уже 1000000 точек (106), а в гиперкубе размерностью 10 и с длиной стороны, равной 1, — уже 1020 точек. Следовательно, чтобы при добавлении новых измерений выборка по-прежнему охватывала пространство должным образом (иными словами, чтобы плотность математического пространства оставалась неизменной), объемы выборок должны возрастать экспоненциально. Допустим, что мы хотим найти закономерности в результатах парламентских выборов и располагаем множеством данных об избирателях и их предпочтениях. Часть имеющихся данных, к примеру рост избирателей, возможно, не будет иметь отношения к результатам голосования. В этом случае лучше исключить переменную «рост», чтобы повысить плотность выборок избирателей в математическом пространстве, где мы будем работать.
Именно проклятие размерности стало причиной появления целого раздела статистики под названием отбор характеристик (англ, feature selection). В этом разделе изучаются различные математические методы, позволяющие исключить максимально большой объем данных, не относящихся к рассматриваемой задаче. Методы отбора характеристик могут варьироваться от исключения избыточной или связанной информации до исключения случайных данных и переменных, имеющих постоянное значение (то есть переменных, значения которых на множестве выборок практически не меняются). В качестве примера приведем переменную «гражданство».
Логично, что ее значение будет одинаковым для всех или почти всех избирателей, следовательно, эта переменная не имеет никакой ценности.
Чаще всего используется такой метод отбора характеристик, как метод главных компонент. Его цель — определение проекции, в которой вариация данных будет наибольшей. В примере, представленном на следующем рисунке, две стрелки указывают две главные компоненты с максимальной вариацией в облаке точек. Максимальная вариация указана более длинной стрелкой. Если мы хотим снизить размерность данных, то две переменные, откладываемые на осях абсцисс и ординат, можно заменить новой переменной — проекцией выборок на компоненту, указываемую длинной стрелкой.
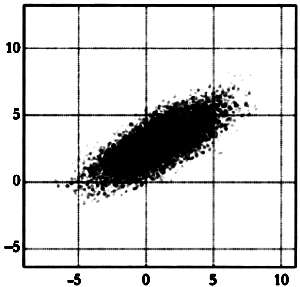
На этом графике стрелки указывают направления, в которых вариация данных будет наибольшей.
* * *
А ЭТО КТО? РАСПОЗНАВАНИЕ ЛИЦ
Многие современные фотоаппараты способны во время съемки распознавать лица. Например, цифровые фотоаппараты часто содержат функцию, позволяющую определить число лиц на фотографии и автоматически настроить параметры съемки так, чтобы все лица оказались в фокусе.
Социальная сеть Facebook также использует функцию распознавания лиц, способную определять людей на фотографиях, загружаемых пользователем. Как же действуют подобные функции?

Большинство функций распознавания лиц основаны на методе главных компонент. Сначала проводится обучение системы на множестве изображений различных лиц. В ходе обучения система определяет главные компоненты в результате анализа нескольких фотографий одного лица и множества фотографий всех лиц. В действительности система всего лишь запоминает наиболее характерные черты лица каждого человека, чтобы потом распознать его.
Таким образом, для нового изображения система извлекает информацию о главных компонентах и сравнивает ее с информацией о компонентах, полученной в ходе обучения. В зависимости от процента совпадения система способна определить, какая часть тела изображена на фотографии, лицо или нога, и даже распознать, какому человеку принадлежит это лицо.
* * *
Метод главных компонент заключается в поиске линейного преобразования, позволяющего получить новую систему координат для исходного множества выборок.
В этой системе координат первая главная компонента будет отражать наибольшую вариацию, вторая — следующую по величине вариацию и так далее. Число компонент может быть любым. Одно из преимуществ этого метода заключается в том, что на промежуточных этапах поиска компонент с наибольшей вариацией можно определить, какую часть вариации переменных объясняет каждая компонента. К примеру, первая главная компонента может объяснить 75 % вариации, вторая — 10 %, третья — 1 % и так далее. Так можно уменьшить размерность множества данных и при этом гарантировать, что новые измерения, которые придут на смену исходным, будут объяснять минимум вариации данных. Рекомендуется, чтобы вариация, в сумме описываемая выделенными компонентами, составляла около 80 %.
Несмотря на все преимущества и относительную простоту метода главных компонент (сегодня этот метод входит в стандартную поставку всех пакетов статистических программ), по мере увеличения числа измерений в модели сложность расчетов возрастает, и вычисления могут оказаться непосильными. В подобных случаях используются два других метода отбора характеристик: жадный прямой отбор (greedy forward selection) и жадное обратное исключение (greedy backward elimination). Оба этих метода обладают серьезными недостатками: они требуют выполнения огромного объема расчетов, при этом вероятность выбора наиболее подходящих характеристик невысока. Однако основная идея этих методов и ее реализация просты, а объем необходимых вычислений для большого числа измерений все же не так высок, как при использовании метода главных компонент. Это объясняет, почему жадный прямой отбор и жадное обратное исключение стали так популярны среди специалистов по интеллектуальному анализу данных.
* * *
ЖАДНЫЕ АЛГОРИТМЫ
Жадные алгоритмы — разновидность алгоритмов, в которых для определения следующего действия (при решении задач планирования, поиска или обучения) всегда выбирается вариант, ведущий к максимальному увеличению некоего градиента в краткосрочной перспективе.
Достоинство жадных алгоритмов заключается в том, что они способны очень быстро найти максимальное значение определенных математических функций. Для сложных функций, имеющих несколько максимумов, жадные алгоритмы, напротив, обычно останавливаются на одном из локальных максимумов, так как не могут оценить задачу в целом. В итоге жадные алгоритмы оказываются не вполне эффективны, так как результатом их работы часто является субоптимум функции.
* * *
Как следует из названия, один из этих методов является прямым, а другой — обратным, однако оба используют один принцип. Представьте, что мы хотим отобрать характеристики, точнее всего описывающие тенденции голосования на парламентских выборах. Имеем пять известных характеристик выборки: покупательная способность, родной город, образование, пол и рост избирателя. Будем использовать для анализа тенденций нейронную сеть. Применив жадный прямой отбор, выберем первую переменную в задаче и смоделируем данные с помощью нейронной сети, используя только эту переменную. После того как модель построена, оценим точность прогноза и сохраним полученную информацию. Повторим аналогичные действия для всех остальных переменных по отдельности. По завершении анализа выберем переменную, для которой были получены лучшие результаты, и повторим моделирование с последующей оценкой модели, но уже для двух переменных. Предположим, что лучшие результаты были получены для переменной «образование». Проверим все возможные сочетания переменных, в которых первой переменной будет «образование». Получим модели «образование и родной город», «образование и пол», «образование и рост». И вновь, проанализировав четыре сочетания, выберем лучшее из них, к примеру «образование и покупательная способность», после чего повторим описанные выше действия уже для трех переменных, две из которых будут фиксированы. Этот процесс будет повторяться до тех пор, пока с добавлением очередной переменной точность новой модели относительно предыдущей, содержащей на одну переменную меньше, не перестанет возрастать.
Жадное обратное исключение проводится прямо противоположным образом: в качестве исходной выбирается модель, содержащая все переменные, затем из нее последовательно исключаются переменные так, чтобы качество модели не ухудшалось.
Как можно догадаться, этот метод является не слишком интеллектуальным: он не гарантирует, что будет найдено наилучшее сочетание переменных, а также предполагает значительный объем вычислений, поскольку на каждом этапе необходимо выполнять моделирование заново.
Ввиду важных недостатков существующих методов отбора характеристик на специализированных конференциях постоянно предлагаются новые методы. Они обычно описываются тем же принципом, что и метод главных компонент, то есть заключаются в поиске новых переменных, которые замещают исходные и повышают плотность информации. Подобные переменные называются латентными. Они используются во множестве дисциплин, однако наибольшее распространение получили в общественных науках. Такие характеристики, как качество жизни в обществе, доверие участников рынка или пространственное мышление человека, — латентные переменные, которые нельзя измерить напрямую. Они измеряются и выводятся по результатам совокупного анализа других, более осязаемых характеристик. Латентные переменные обладают еще одним преимуществом: они сводят несколько характеристик в одну, тем самым уменьшая размерность модели и упрощая работу с ней.
Визуализация данных
Визуализация данных — дисциплина, изучающая графическое представление данных, как правило многомерных. Эта дисциплина стала популярной вскоре после образования современных государств, способных систематически собирать данные о развитии экономики, общества и производственных систем. В действительности визуализация данных и анализ данных — смежные дисциплины, так как многие средства, методы и понятия, используемые для упрощения визуализации, возникли в рамках анализа данных, и наоборот.
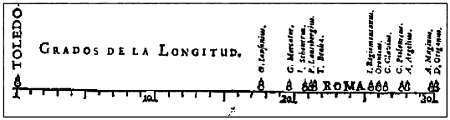
Возможно, автором первой известной визуализации статистических данных был Михаэль ван Лангрен, который в 1644 году изобразил на диаграмме 12 оценок расстояния между Толедо и Римом, предложенных 12 разными учеными. Слово «ROMA» («РИМ») указывает оценку самого Лангрена, а маленькая размытая стрелка, изображенная под линией примерно в ее центре, — корректное расстояние, вычисленное современными методами.
Еще в XVIII веке Джозеф Пристли составил диаграмму, где изобразил, в какое время жили некоторые выдающиеся деятели античности.
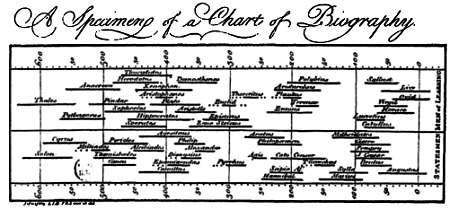
В том же столетии, благодаря трудам Иммануила Канта, который утверждал, что именно представление делает объект возможным, а не наоборот, стало понятно, что нельзя вести споры о знаниях или реальности, не учитывая, что эти самые знания и реальность создает человеческий разум. Так представление и визуализация данных заслуженно заняли важнейшее место в науке.
Позднее, во время Промышленной революции, начали появляться более сложные методы представления данных. В частности, Уильям Плейфэр создал методы, позволяющие представить изменение объемов производства, связав их с колебаниями цен на пшеницу и с величиной заработной платы при разных правителях на протяжении более 250 лет.
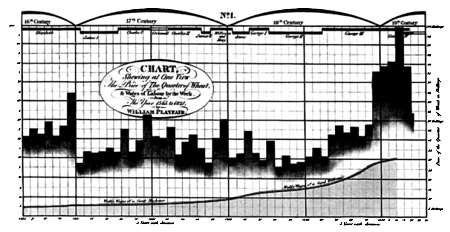
Благодаря вычислительной технике специалисты в сфере визуализации данных начали понимать, каким должно быть качественное представление данных для их быстрой интерпретации. Один из важнейших моментов, которые следует принимать во внимание (помимо самих данных, модели представления и графического движка, используемого для визуализации), — ограниченные способности восприятия самого аналитика, конечного потребителя данных. В мозгу аналитика происходят определенные когнитивные процессы, в ходе которых выстраивается ментальная модель данных. Однако эти когнитивные процессы страдают из-за ограниченности нашего восприятия: так. большинство из нас неспособны представить себе больше четырех или пять измерений. Чтобы упростить построение моделей, необходимо учитывать все эти ограничения. Качественная визуализация данных должна представлять информацию в иерархическом виде с различными уровнями подробностей. Также визуализация должна быть непротиворечивой и не содержать искажений. В ней следует свести к минимуму влияние данных, которые не содержат полезной информации или могут вести к ошибочным выводам. Рекомендуется дополнять визуализацию иными статистическими данными, указывающими статистическую значимость различной информации.
Для достижения всех этих целей используются стратегии, подобные рассмотренным в главе, посвященной анализу данных. Первая из них заключается в снижении размерности с помощью уже описанных методов, в частности, путем ввода латентных переменных. Вторая стратегия состоит в снижении числа выборок модели путем их разделения на значащие группы. Этот процесс называется кластеризацией (английское слово «кластер» можно перевести как «гроздь», «пучок»).
Кластерный анализ состоит в разделении множества результатов наблюдений на подмножества — кластеры, так, чтобы все результаты, принадлежащие к одному кластеру, обладали некими общими свойствами, необязательно очевидными. Кластеризация данных значительно упрощает их графическое представление, а также позволяет специалистам по визуализации понять изображаемые данные. Существует множество алгоритмов кластеризации, и каждый из них обладает особыми математическими свойствами, которые делают его пригодным для тех или иных типов данных.
Распознавание образов
В главе об анализе данных нельзя обойти стороной тему распознавания образов как одну из основных целей анализа. Для распознавания образов можно использовать все описанные выше средства: нейронные сети, метод опорных векторов, метод главных компонент и другие. Как вы видите, распознавание образов имеет непосредственное отношение к машинному обучению.
Цель системы-классификатора, подобно нейронной сети или методу опорных векторов, — предсказать, к какому классу относится данная выборка, то есть классифицировать ее. Поэтому системе-классификатору в целях обучения следует передать множество выборок известных классов. После обучения системы ей можно будет передавать для классификации новые выборки. Как и в описанных выше методах, начальное множество выборок известных классов обычно делится на два подмножества — обучающее и тестовое. Тестовое множество помогает проверить, не переобучена ли система.
При создании классификаторов применяются два подхода: мичиганский, предложенный исследователями из Мичиганского университета, и питтсбургский, появившийся, соответственно, в университете города Питтсбурга. В мичиганском подходе описывается эволюционный алгоритм, в котором в роли эволюционирующих особей выступают правила, каждое правило содержит множество условий и цель.
Класс выборки укажет правило, с набором условий которого совпадает выборка.
В питтсбургском подходе, напротив, каждая особь представляет собой множество правил, а приспособленность особи оценивается по средней ошибке для каждого из этих правил. Оба подхода, которые в немалой степени дополняют друг друга, имеют свои преимущества и недостатки. В последние 30 лет исследователи предлагают различные улучшения обоих подходов, чтобы компенсировать их неэффективность.
Практический пример: анализ продаж
Еще одна важная область применения искусственного интеллекта в бизнесе — это работа с хранилищами данных, которые широко используются предприятиями с большой клиентской базой и, следовательно, с большой базой выборок. Путем анализа базы выборок можно определить тенденции, закономерности и шаблоны поведения. Хранилище данных — это место, куда стекаются данные со всего предприятия, будь то данные о продажах, производстве, результатах маркетинговых кампаний, внешних источниках финансирования и так далее. Сегодня хранилища данных используются в таких областях, как банковская сфера, здравоохранение, розничная торговля, нефтепереработка, государственная служба и другие.
Создание и структурирование хранилища данных — сложная задача, на решение которой инженерам потребуется несколько месяцев и даже лет. После того как хранилище данных выстроено, структурировано и обеспечена его корректность, содержащиеся в нем данные изучаются и анализируются с помощью так называемых OLAP-кубов, которые в действительности представляют собой гиперкубы. OLAP-куб (от англ. OnLine Analytical Processing — «аналитическая обработка в реальном времени») — это многомерная структура данных, позволяющая очень быстро выполнять перекрестные запросы к данным различной природы. О LAP-куб можно считать многомерным вариантом электронной таблицы. К примеру, электронная таблица, в которой представлены данные о продажах молочных продуктов нашей компании в разных странах в прошлом году (в тысячах штук), может выглядеть так.
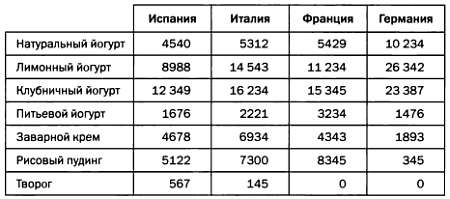
Если мы хотим получить данные о продажах в отдельные месяцы, нужно добавить к таблице третье измерение, в котором для каждого региона и типа продукции представленные данные будут разбиты на 12 месяцев.
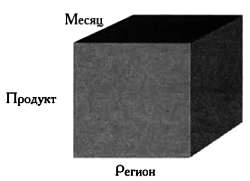
Сформировав куб, мы сможем выполнять различные виды сложного анализа данных с учетом предварительно выстроенной структуры куба. Заметим, что основные затраты вычислительных ресурсов при использовании хранилища данных связаны не с самим анализом данных, а с построением множества гиперкубов. Гиперкубы могут отражать данные организации с учетом множества возможных сочетаний. Поэтому OLAP-кубы, как правило, строятся по ночам, а используются и анализируются на следующий день.
С помощью OLAP-кубов аналитики компании, производящей молочные продукты, могут ввести в систему новое измерение — погодные условия в каждый день года в каждом регионе, где продаются продукты компании. Это новое измерение позволит изучить уровень потребления различных продуктов в зависимости от температуры.
Располагая этими знаниями и прогнозами погоды, аналитики могут предсказать, какой объем всех видов продукции следует произвести в каждом регионе, чтобы свести запасы молочной продукции к минимуму. Отметим, что соблюдение температурного режима хранения молочных продуктов требует немалых расходов.
Часто измерения OLAP-кубов дополнительно усложняются, и в пределах одного измерения вводятся иерархии. Так, в предыдущем примере измерение, описывающее погоду, можно дополнить новой иерархией, например привести данные о погоде за каждый день или в каждом квартале, так как уровень потребления молочных продуктов будет гарантированно отличаться летом и зимой, в начале и в конце месяца.
Можно сформировать иерархию регионов и ввести как более крупные (Центральная Европа, Южная Европа), так и более мелкие области (Ломбардия, Бретань, Андалусия).
Разумеется, после завершения построения с помощью OLAP-кубов можно решать различные задачи визуализации данных, помимо очевидного анализа, о котором мы уже рассказывали. К примеру, можно изображать двухмерные сечения куба или отдельные «кубики» (небольшие многомерные части куба), складывать или вычитать значения в рамках иерархий и даже вращать куб, чтобы взглянуть на данные с другой стороны.
* * *
MICROSOFT RESEARCH
Сегодня крупнейшим коммерческим исследовательским центром мира, где ведутся работы по изучению искусственного интеллекта, является Microsoft Research. В этом центре работают авторитетные ученые, которые занимаются изучением столь важных вопросов, как машинное обучение или новые способы взаимодействия человека и машины. Microsoft Research имеет представительства в самых разных странах, в частности в Германии, США, Великобритании, Китае, Индии и Египте.
Специалисты центра являются мировыми лидерами в области использования байесовских сетей и других вероятностных методов в таких областях, как обнаружение нежелательных писем (спама) или интеллектуальная адаптация интерфейса информационных систем к шаблонам поведения пользователей.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Глава 3 Анализ
Глава 3 Анализ А что такое эти флюксии? Скорости исчезающих приращений. А что такое эти самые исчезающие приращения? Они не есть ни конечные величины, ни величины бесконечно малые, но они и не нули. Разве мы не имеем права назвать их призраками исчезнувших величин? Епископ
Анализ периодичности кометы Галлея. Список дат её появления
Анализ периодичности кометы Галлея. Список дат её появления Начнем со списка дат, обычно считающихся датами появления кометы Галлея. Список разбивается обычно на две части: китайские записи о комете Галлея и европейские. Приведем оба списка в сравнении друг с
Глава 7 Запоминающаяся глава для запоминания чисел[9]
Глава 7 Запоминающаяся глава для запоминания чисел[9] Наиболее часто мне задают вопрос о моей памяти. Нет, сразу скажу я вам, она у меня не феноменальная. Скорее, я применяю систему мнемотехники, которая может быть изучена любым человеком и описана на следующих страницах.
Глава 2
Глава 2 1. История первая. По существу, Болванщик заявил, что варенье украли либо Мартовский Заяц, либо Соня. Если Болванщик солгал, то ни Мартовский Заяц, ни Соня не украли варенье. Но тогда Мартовский Заяц, поскольку он не украл варенье, дал правдивые показания.
Глава 3
Глава 3 14. Гусеница и Ящерка Билль. Гусеница считает, что и она, и Ящерка Билль не в своем уме. Если бы Гусеница была в здравом уме, то мнение о том, что и она, и Ящерка Билль не в своем уме, было бы ложно. Следовательно, Гусеница (будучи в здравом уме) не могла бы придерживаться
Глава 11
Глава 11 88. Всего лишь один вопрос. Действительно следуют. Рассмотрим сначала утверждение 1. Предположим, некто убежден, что он бодрствует. В действительности он либо бодрствует, либо не бодрствует. Предположим, что он бодрствует. Тогда его убеждение правильно, но всякий,
Глава 7
Глава 7 graphics54 64. Первый раундЕсли бы братец говорил правду, его звали бы Траляля и у него была бы карта черной масти. Но он не может говорить правду, если у него в кармане карта черной масти. Поэтому он лжет. Это означает, что у него действительно карта черной масти, а
Глава 1. Что такое анализ бесконечно малых и для чего он нужен
Глава 1. Что такое анализ бесконечно малых и для чего он нужен Анализ бесконечно малых — это область математики, которая имеет огромное значение для науки и техники. Чтобы понять, из чего состоит эта сложная и тонкая дисциплина, наверное, следует начать с рассказа о
Ньютон и анализ бесконечно малых
Ньютон и анализ бесконечно малых Исаак Ньютон — один из самых известных и уважаемых ученых всех времен. Хотя это часто не принимается во внимание, но он в наибольшей степени обязан этой славе своим способностям к математике. Именно благодаря им он заметно выделялся среди
Лейбниц и анализ бесконечно малых
Лейбниц и анализ бесконечно малых «Почти все остальные крупные математики, — писал в XX веке Иозеф Хоффман, видный исследователь биографии Лейбница, — увлекались математикой уже в юные годы и разрабатывали радикально новые идеи. Однако этот период в жизни Лейбница не был
Эйлер и анализ бесконечно малых
Эйлер и анализ бесконечно малых Если Ньютон и Лейбниц считаются создателями дифференциального и интегрального исчисления, то Эйлера можно назвать создателем математического анализа — области математики, куда входят оба эти раздела. В этом смысле его книги «Введение в