Глава 6 Хорошо кончается то, что не кончается
Глава 6
Хорошо кончается то, что не кончается
Чтобы получить даже мельчайшую крупицу нового знания, требуется долгое и трудное самоотречение, пойти на которое готовы лишь немногие, чистые душой.
Маргерит Дюрас
Возможно, он знал, что делал, когда повел ее в ресторан, куда ходили только японцы. Возможно, он не сомневался в своем обаянии. Если ему не удастся поразить спутницу начитанностью и рассказами о своих путешествиях, он еще может спасти свидание, удивив ее одним из экзотических блюд. Когда официантка, не столь красивая, как того требует история, осведомилась о выборе десерта, все складывалось благополучно. Он немного знал японский, поэтому когда официантка спросила, как следует приготовить чайный трюфель: «со сливками, без сливок или как-то еще», мужчина, хоть и был несколько смущен, тем не менее решительно сказал: «Как-то еще». Вскоре официантка вернулась и, улыбаясь, подала тарелку трюфелей, на которой было налито совсем немного сливок, не касавшихся самого блюда. Мужчина и женщина посмотрели друг на друга и одновременно сказали: «Проклятые азиаты! Им неизвестен принцип непротиворечивости».
Нечеткая логика
Несмотря на внешние различия, все множества, которые мы рассмотрели до этого, обладали одним общим свойством: для любого элемента и любого множества на вопрос «Принадлежит ли этот элемент множеству?» можно было дать только один ответ: да или нет. Описание множества могло быть каким угодно сложным, но ответом на этот вопрос обязательно было бы «да» или «нет». Именно это произошло в примере с числами, десятичная запись которых содержит все возможные последовательности и о которых мы рассказали в предыдущей главе. Неизвестно, принадлежит ? этому множеству или нет, но в любом случае на этот вопрос можно дать только один ответ. Предложения логики также подчиняются этой схеме: они либо истинны, либо ложны, и любая другая возможность исключается. Более того, два основных парадокса, которые мы рассмотрели (парадокс Рассела и парадокс лжеца), возникают именно тогда, когда даже с теоретической точки зрения невозможно ответить на вопрос «да» или «нет», невозможно определить, принадлежит некий элемент множеству или нет. Дело не в том, что закон исключенного третьего допускает исключения, а в том, что множество всех множеств, которые не являются элементами самого себя, и выражение «эта фраза ложна» формально некорректны, потому что отношение принадлежности справедливо только для объектов разных типов, а также потому, что понятие истинности принадлежит не языку, а метаязыку.
В некотором смысле теория множеств и логика находятся на вершине отвесной скалы: истинное расположено на самом краю, и достаточно легкого дуновения ветерка, чтобы отправиться в свободное падение по направлению к ложному. Однако большую часть земной поверхности занимают не отвесные скалы, а пологие склоны.
Несколько лет назад во многих странах произвела настоящий фурор настольная игра Scattergories. В этой игре нужно выбрать любую букву алфавита, а затем записать слова из разных областей, которые начинаются с этой буквы. Например, если нам дан список «Спорт. Названия песен. Части тела. Национальная кухня. Оскорбления» и после броска игральной кости, которая имеет форму икосаэдра, выпала буква «К», ответ может звучать так: «Кёрлинг. «Катюша». Колено. Кулебяка. Кретин!». В рекламе игры Scattergories расстроенный мальчик уходит из дома, унося игру с собой, потому что его друзья сказали, что «корабль» не относится к категории «морские животные». В конце концов они решают уступить ему, так как хотят продолжить игру, но в следующем туре мальчик вновь принимается за старое: когда выпадает буква «О», он спрашивает друзей: «А осьминога можно назвать домашним животным?»
В то время как некоторых живых существ затруднительно причислить к животным, множество домашних животных определено еще хуже: к нему, конечно же, принадлежат кошки и собаки, и так же совершенно однозначно в него не входят волки и слоны. Однако хотя некоторые причислят тарантулов к множеству «животных, к которым я не хочу подходить ближе, чем на километр», другие развлекаются тем, что бросают тарантулам сверчков между прутьями клетки. Так же нечетко, как и множество домашних животных, определены и другие множества, с которыми мы имеем дело каждый день, например множество красивых людей, хороших ресторанов и смешных шуток. Первым предложил теорию, описывающую подобные ситуации, польский логик Ян Лукасевич (1878–1956). В 1917 году он представил трехзначную логику, в которой высказывания могли быть не только истинными или ложными, но и «возможными». Например, человек ростом 1,50 м низкий, человек ростом 2 м — высокий, а тот, чей рост составляет 1,75 м, является «возможно, высоким» или «возможно, низким» — все зависит от того, с кем мы его сравниваем: с пигмеями или игроками НБА.
* * *
МЕСТЬ ЛЖЕЦА
Если мы вновь рассмотрим парадокс лжеца, на этот раз с точки зрения трехзначной логики Лукасевича, то увидим, что противоречие исчезает: основа наших рассуждений заключалась в том, что если высказывание «эта фраза ложна» не является истинным, то оно обязательно является ложным. Однако в новой логике существуют высказывания, которые являются не истинными и не ложными, а возможными. Поскольку суть парадокса не сводится исключительно к закону исключенного третьего, его можно переформулировать так, что он сохранится и в трехзначной логике. Рассмотрим высказывание «эта фраза не является истинной». Все высказывания делятся на три класса (истинные, ложные и возможные), поэтому мы рассмотрим каждый класс по очереди. Если высказывание истинно, то оно должно выполняться, следовательно, оно не будет истинным. Если, напротив, высказывание является ложным или возможным, тогда оно не является истинным и, следовательно, должно быть истинным. В новой логике определить истинность высказывания «эта фраза не является истинной» по-прежнему невозможно.
* * *
Включение в перечень возможных значений истинности значения «возможно» стало настоящим прорывом за пределы черно-белого мира классической логики.
Однако этого прорыва оказалось недостаточно: значение «возможно» само по себе никак не помогает нам принимать решения. Допустим, что журналист решил подать в отставку после смены редакционной политики издания. Обозначим через Р высказывание «я не согласен с новой политикой редакции». Следовательно, классическое решение будет выглядеть так: «Если Р истинно, я ухожу» и «Если Р ложно, я остаюсь». Так как любое решение всегда сопровождается множеством тонкостей, журналист с радостью согласился бы иметь возможность выбора из трех вариантов.
Но как в этом случае следует понимать значение «возможно»? Если Р возможно, то нужно уходить в отставку или оставаться? Что отделяет одно решение от другого? Если мы хотим, чтобы наша логика позволяла принимать подобные решения, необходим более высокий уровень точности.
И здесь на сцену выходит профессор Калифорнийского университета в Беркли Лотфи Заде, который в 1965 году предположил, что значение принадлежности элемента множеству или значение истинности высказывания может описываться любым числом, лежащим на интервале от 0 до 1. Таким образом, игроки в Scattergories могут установить, что правильными ответами будут, например, только те, что принадлежат рассматриваемому семантическому полю более чем на 0,6, а журналист может решить уйти в отставку, если степень его несогласия с новой редакционной политикой будет превышать, допустим, 0,45. Заде обозначил новые множества английским словом fuzzy, которое можно перевести как «нечеткое, не имеющее четко обозначенных пределов». Следовательно, на вопрос о принадлежности элемента нечеткому множеству существует бесконечно много ответов.

Создатель нечеткой логики Лотфи Заде
(источник: Вольфганг Хюнше).
Читатель, возможно, поддастся искушению интерпретировать нечеткие множества в терминах теории вероятностей. Возможно, в этом случае объяснение станет более понятным, но говорить, что степень принадлежности элемента к множеству является вероятностью того, что он принадлежит к этому множеству, некорректно — это идет вразрез с духом нечеткой логики, предложенной Заде. Посмотрим, что происходит, когда мы бросаем в воздух монету. Мыс детства знаем, что вероятность выпадания решки равна 50 %, и это означает, что если мы подбросим монету много раз, например 10 тысяч, то примерно в половине случаев выпадет орел, в половине — решка. Но результат каждого броска будет единственным: орел или решка. Вероятность, по меньшей мере в упрощенной трактовке, отражает ограниченность наших знаний о ситуации: если бы нам с абсолютной точностью была известна сила, с которой мы подбросили монету, если бы мы могли уподобиться богу Эолу и повелевать ветрами, то смогли бы с точностью предсказать результат броска монеты. Это означает, что глубинный принцип, лежащий в основе теории вероятностей в ее простейшем понимании, совпадает с принципом классической логики, в то время как в мире нечетких множеств при броске монеты может выпасть решка, скорее решка, чем орел, скорее орел, чем решка, орел или любое из промежуточных значений, выраженных с бесконечной точностью.
В отличие от классических множеств, граница которых подобна отвесному утесу, множества, изучаемые в нечеткой логике, определяются функцией принадлежности, которая воспроизводит форму пологого склона. Рассмотрим в качестве примера множество высоких людей. Если считать, что люди ниже 1,60 м низкие, выше 1,90 м — высокие, то функция принадлежности этого множества примет следующий вид:
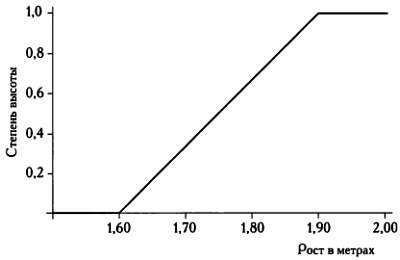
Функция принадлежности нечеткого множества высоких людей. График функции имеет форму склона.
Выполнив некоторые вычисления, можно доказать, что степень принадлежности тех, чей рост менее 1,60 м, к множеству высоких людей равна 0. Если рост человека больше или равен 1,90 м, он будет абсолютно точно считаться высоким, а если его рост находится на интервале между этими двумя значениями, то для определения степени принадлежности к множеству нужно умножить его рост в метрах на 10, вычесть 16, а затем разделить полученное число на 3. Если известно, что степень высоты человека равна 0,3, как, например, для автора этой книги, то этого достаточно, чтобы определить его рост.
В других случаях график функции принадлежности может иметь форму треугольника или трапеции. Если считать, например, что «слишком холодно» — это любая температура ниже +10 °C, «слишком жарко» — температура выше +30 °C, а идеальная температура находится на интервале между +18 и +22 *С, то график функции принадлежности ко множеству благоприятных температур будет напоминать изображенный на рисунке ниже. Если мы сравним этот график с климатограммами для разных городов, то сможем выбрать тот, где будет комфортнее всего жить, или, по крайней мере, исключим совсем уж неподходящие варианты.
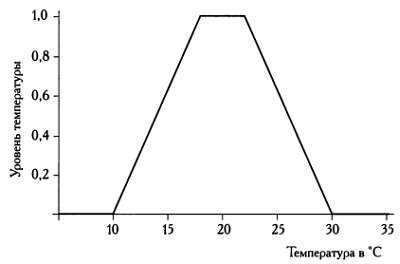
Функция принадлежности нечеткого множества благоприятных температур. График функции имеет форму трапеции.
Нечеткие множества, имитирующие шкалу оттенков серого, описывающую реальность, помогают разрешить некоторые парадоксы, поскольку благодаря им мы можем рассматривать понятия в самом широком смысле. Представим, что в кафе нам подали очень горький кофе. Скорее всего, прежде чем выпить кофе, вы добавите в него немного сахара. Нет сомнений, что если мы добавим в чашку единственную крупинку сахара, вкус совершенно не изменится. Следовательно, действие «добавить крупинку сахара» не влияет на горечь кофе. Добавим еще одну крупинку сахара, затем еще и еще одну — всего десять ложек сахара. Если наше исходное предположение верно и ни на одном шаге вкус не изменился, значит кофе, в который добавлено десять ложек сахара, по вкусу ничем не будет отличаться от горького кофе, который нам подали в начале, — этот результат выглядит, по меньшей мере, подозрительно. Нетрудно понять, что ситуация не описывается классическими множествами, о которых мы говорили в предыдущей главе. Горький кофе, который невозможно пить, и слишком сладкий, приторный кофе разделяет не бездна, а пологий склон. Хотя мы не способны ощутить изменение вкуса кофе при добавлении в него всего одной крупинки сахара, степень принадлежности ко множеству «кофе, приятного на вкус» возрастет, сколь бы малым ни было изменение вкуса. Если мы добавим в кофе еще одну крупинку, степень принадлежности к этому множеству возрастет еще больше, и, наконец, когда мы добавим в кофе в общей сложности десять ложек сахара, его вкус станет невыносимо приторным.
При обобщении любого математического понятия (это и попытался совершить Заде, введя нечеткую логику) нужно обязательно убедиться в том, что новая теория корректна для всех исходных объектов. Классические множества являются частными случаями нечетких множеств: для них функция принадлежности из всего бесконечного множества значений принимает только два значения: 0 и 1. Тем не менее отношение включения множества в другое, а также операции объединения и пересечения, которые, как вы увидели в главе 3, являются основными в теории множеств, обобщить не так просто. На эти и другие вопросы Заде дал ответ в своей статье, опубликованной в 1965 году.
Обозначим как А и В два нечетких множества, соответствующие функции принадлежности к которым мы будем обозначать fA и fB. Это означает, что для данного элемента х число fA (х), указывающее степень принадлежности х к множеству А, заключено в интервале от 0 до 1, и это же верно для fB(х). Использовав эту нотацию, Заде установил, что А включено в В тогда, когда для любого элемента х число fA (х) меньше или равно fB(х).
Рассмотрим пример. Вместо того чтобы считать людей ниже 1,60 м низкими, выше 1,90 м — высокими, мы понизим границу множества и будем считать низкими людей ниже 1,50 м, далее степень принадлежности ко множеству будет постепенно возрастать, как и ранее, до значения 1,90 м. Таким образом мы получим еще одно нечеткое множество высоких людей. Степень принадлежности автора к этому множеству будет равна уже не 0,5, а 0,625. Согласно Заде, первое множество содержится во втором, и это соответствует интуитивному представлению о том, что высокие люди остаются таковыми, даже если снизить нижнюю границу множества.
Описав нечеткую логику, Лотфи Заде, изучавший электротехнику, предположил, что новую логику можно применить при обработке информации и распознавании образов — в двух областях, где нечеткость играет определяющую роль. История показала, что Заде недооценил свою идею, и наиболее широко созданная им логика применяется именно в той стране, жители которой едят чайные трюфели «со сливками, без сливок или как-то еще». В конце 90-х годов в японских магазинах начали продаваться копировальные аппараты и стиральные машины с нечеткой логикой, а в небоскребах Токио стали устанавливать лифты, нечеткая логика которых позволяла сводить время ожидания к минимуму. Как говорилось в рекламном ролике одной из этих стиральных машин, наступила нечеткая эра.
* * *
СТИРАЛЬНЫЕ МАШИНЫ С НЕЧЕТКОЙ ЛОГИКОЙ
Чтобы оптимизировать длительность и качество стирки, полезно точно указать, является одежда очень грязной, слегка грязной или практически чистой. Простейшие стиральные машины с нечеткой логикой присваивают каждой загрузке белья значение загрязнения от 0 до 1. Затем к фиксированному интервалу стирки продолжительностью в десять минут добавляется определенное время в зависимости от степени загрязнения одежды. Машина может, например, определить, что для чистого белья (0) достаточно базового времени стирки, а для очень грязного (1) — на две минуты больше. Следовательно, если мы положим в стиральную машину слегка грязную рубашку, продолжительность стирки увеличится на одну минуту. В других, более сложных моделях, с целью экономии электроэнергии учитывается степень жирности (жирные пятна отстирываются тяжелее других) и вес загруженного белья.
* * *
Сложность
«Любовь» и «справедливость» — слишком расплывчатые понятия, чтобы их можно было описать двоичной логикой. Множество оттенков серого, простирающееся между «он меня любит» и «он меня не любит», между виной и невиновностью, описывается нечеткой логикой. С ростом сложности возникает потребность в новом мышлении. Следовательно, полезно ввести оценку сложности понятий, однако само понятие «сложность» не поддается попыткам дать ему определение. Даже в царстве математики, где правит абсолютная точность, нельзя однозначно отделить сложные проблемы от простых. Именно это происходит и с машинами Тьюринга: если в прошлой главе работа с идеальными компьютерами позволила нам получить теоретические результаты, касающиеся проблем, которые не может решить машина, то теперь нас интересует, какие расчеты она может провести с учетом ограничений в объеме памяти и времени выполнения программ. Именно так, за неимением лучшего определения, мы будем отличать простые задачи от сложных.
В первом приближении мы можем определить сложность как число операций, необходимых для решения задачи. Представим коммивояжера, которому нужно посетить несколько городов, после чего вернуться в исходный. Следовательно, его целью будет максимально сократить пройденный путь. Если этими городами будут, например, Париж (П), Лондон (Л), Берлин (Б) и Рим (Р) и коммивояжер начинает поездку в Париже, то его секретарь может составить расписание шестью разными способами: ПЛБРП, ПЛРБП, ПБЛРП, ПБРЛП, ПРБЛП и ПРЛБП. Учитывая примерные расстояния Париж — Лондон (455 км), Париж — Берлин (1050 км), Париж — Рим (1435 км), Лондон — Берлин (1095 км), Лондон — Рим (1855 км) и Берлин — Рим (1515 км), можно рассчитать общую длину каждого маршрута и выбрать кратчайший из них:
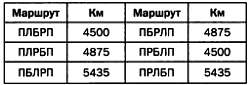
Учитывая данные, представленные в таблице, оптимальным будет маршрут Париж — Лондон — Берлин — Рим — Париж или он же, но в обратном направлении: Париж — Рим — Берлин — Лондон — Париж. Но что произойдет, если коммивояжеру нужно будет посетить не три города, а четыре, пять или любое другое количество городов? Для решения этой задачи всего для двадцати городов компьютеру средней производительности потребуется 80 тысяч лет, и в свете этого возможная потеря времени от неправильного выбора маршрута уже несущественна.
Если мы попытаемся решить задачу «грубой силой», то потребуется рассмотреть уже не шесть случаев — их число будет равно произведению 1·2·3· … и т. д. до 20. Запись этого числа содержит девятнадцать цифр. В математике это число называется 20 факториал и обозначается восклицательным знаком после числа. Так, 3! = 1·2·3 = 6; 4! = 1·2·3·4 = 24; в общем случае n! равен произведению первых n натуральных чисел.
Факториал — это пример функции, вычислить значение которой теоретически очень просто, однако на практике компьютеры пасуют перед этой задачей. Как мы уже отмечали в предыдущей главе, все рекурсивные функции являются вычислимыми. Напомним, что функция является рекурсивной, если значение f(n) можно вычислить на основе значений, которые принимает эта функция для чисел, меньших n. Факториал — это классический пример рекурсивной функции, так как если мы хотим вычислить 4! = 1·2·3·4, мы можем сначала найти произведение 1·2·3, а затем умножить его на 4. Но что представляет собой произведение 1·2·3? Оно равно 3! таким образом, если известно значение 3! то чтобы найти 4! достаточно одной операции. В общем случае n! = (n — 1)!·n — это доказывает, что факториал является рекурсивной, а следовательно, и вычислимой функцией. Для машины Тьюринга, способной работать бесконечное время, вычисление n! не представляет трудностей. Но на практике значения факториала возрастают столь быстро, что с ними вскоре становится невозможно работать.
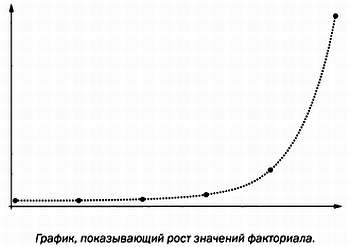
График, показывающий рост значений факториала.
Предыдущий пример был бы не более чем любопытным фактом, если бы факториал не описывал число перестановок элементов конечных множеств, то есть число способов, которыми можно упорядочить их элементы. Так, фразы «3! = 6» и «множество {1, 2, 3} можно записать шестью разными способами (123, 132, 213, 231, 312 и 321)» содержат одинаковую информацию. Так как примитивный метод решения многих задач, схожих с задачей коммивояжера, требует последовательного перебора всех элементов множества, которое может быть достаточно большим, то скорость, с которой возрастают значения факториала, имеет фатальные последствия.
* * *
ИЗОБРЕТАТЕЛЬ ШАХМАТ
По легенде, персидский царь хотел наградить изобретателя шахмат и подарить ему все, что он пожелает. Тогда мудрец удивил царя просьбой, которая показалась скромной: он хотел получить одно зерно за первую клетку доски, два — за вторую, четыре — за третью и т. д. — на каждой клетке доски должно было находиться в два раза больше зерен, чем на предыдущей. Эта просьба показалась царю насмешкой, и он, рассерженный, повелел слугам немедленно исполнить просьбу мудреца и выслать ему столько зерна, сколько тот просил. Каково же было его удивление, когда один из советников на следующий день сообщил ему, что для этого не хватит зерна в амбарах всего мира. Функция, принимавшая значения 1, 2, 4, 8… возрастала столь быстро, что общее число зерен составило 18446744073 709551615.

* * *
В одном из простых определений сложными называются задачи, решение которых требует выполнения сопоставимого числа операций, а простыми считаются те, которые разрешимы не только с теоретической, но и с практической точки зрения, то есть в разумное время. Эти задачи часто обозначаются буквой Р (по первой букве английского слова «полином»), так как число операций для их решения примерно равно некоторому многочлену от времени выполнения.
Ученые заметили, что существуют задачи, найти решение которых очень сложно, а подтвердить его правильность относительно просто. Вернемся к примеру с отелем из главы 2, который на этот раз содержит конечное число комнат. Предположим, что группа из четырехсот человек хочет остановиться в отеле в те дни, когда там будет свободно всего сто номеров. Выбрать сто человек из четырехсот, не следуя какому-либо критерию, очень просто, однако заявка от группы сопровождалась одной странной просьбой: некоторые путешественники настолько не ладили друг с другом, что их нельзя было размещать в соседних номерах. Не стоит и думать, что эту задачу можно решить перебором всех возможных выборок ста человек из четырехсот, но при этом для любого предложенного решения достаточно будет подтвердить, что никакие два путешественника, которые не ладят друг с другом, не будут поселены в соседние номера. С этой задачей сможет справиться администратор отеля даже без помощи компьютера всего за несколько часов. Такие задачи, которые сложно решить, но легко проверить, математики относят к классу NP.
Пока что мы говорили о сложности задач как о неотъемлемой части их формулировки. Эта точка зрения априори ошибочна, так как сложной или простой является не задача сама по себе, а наш способ ее решения. Возможно, найденное нами решение требует выполнения множества операций, но при этом существует другое, более простое. В этом случае наше решение относится к классу NP, в то время как сама задача — к классу Р. Решение задачи о коммивояжере заключалось в переборе всех возможных маршрутов. Однако в таблице показано, что при смене порядка обхода городов на противоположный длина маршрута не меняется. Следовательно, выбор маршрута Париж — Лондон — Берлин — Рим — Париж ничем не отличается от маршрута Париж — Рим — Берлин — Лондон — Париж, поэтому достаточно рассмотреть половину исходных случаев. На практике подобное упрощение не слишком полезно, так как половина огромного числа по-прежнему остается огромным числом. Этот аспект имеет скорее философский характер: если в первом решении мы упустили из вида столь тривиальную деталь, то сколько подобных моментов мы еще не учли? Мы сказали, что наша исходная точка зрения априори ошибочна, поскольку неизвестно, существуют ли задачи, для которых сложность является неотъемлемым свойством их формулировки, а не решений. К числу таких задач, возможно, относится задача о коммивояжере, пока что никому не удалось доказать, что все ее решения являются сложными.
* * *
Р И NP
Как вы увидели в главе 3, датой символического начала математики XX века считается август 1900 года, когда Гильберт обнародовал свой список из двадцати трех задач на конференции в Париже. Вновь в Париже, но уже сто лет спустя, экспертная комиссия из Института Клэя выбрала семь открытых задач, которые, по ее мнению, обозначили направление математических исследований нового столетия. Четвертая проблема в этом списке, известная как проблема равенства классов Р и NP, заключается как раз в том, чтобы подтвердить, существуют ли задачи класса NP сами по себе или же, напротив, любую задачу, решение которой можно проверить за полиномиальное время, также можно быстро решить, найдя некий хитроумный алгоритм. Того, кто найдет решение этой проблемы, ждет премия в один миллион долларов. Как видите, математика иногда может приносить доход.
* * *
В связи с этим определением сложности возникает еще одно замечание: в подобной трактовке не проводится различие между задачами, для решения которых требуется одинаковое число операций. По нашему определению, запомнить пароль из двенадцати символов — это простая или сложная задача независимо от того, из каких символов состоит пароль, так как для этого неизменно потребуется двенадцать действий: запомнить первый символ, второй, третий и т. д. до двенадцатого.
Однако никто, будучи в здравом уме, не скажет, что запомнить пароли 111111111111 и 6u0yfz3eq85s одинаково просто. Первый пароль можно сжать до слов «12 единиц», а второй пароль можно описать только одним способом — посимвольно. В середине 70-х годов советский математик Андрей Колмогоров на основе этого примера ввел новое определение сложности, предложив заменить число операций на число инструкций. Сложность последовательности символов стала определяться как минимальная длина алгоритма, необходимого для ее генерации.
Представим себе машину Тьюринга, задача которой — записать определенную последовательность нулей и единиц, которую мы назовем s. Как вы увидели из предыдущей главы, машине нужно дать последовательность инструкций вида «Если считано 1, сместиться вправо и перейти к инструкции № 2». В этом упрощенном варианте мы говорим, что сложностью s является натуральное число n, если существует машина Тьюринга, описанная посредством n инструкций, выходным значением которой является s, и если никакая машина не может сгенерировать заданную последовательность за меньшее число инструкций. Таким образом определяется функция К (по первой букве фамилии Колмогорова), которая сопоставляет каждой последовательности нулей и единиц ее сложность. Рассмотрим последовательность 1111… Если подать на вход машины Тьюринга ленту, на которой записаны только нули и единственная инструкция которой гласит «Инструкция № 1: Если считан 0, записать 1 и перейти к инструкции № 1. Если считан 1, сместиться вправо и перейти к инструкции № 1», то в результате мы получим последовательность 1111… Это означает, что заданная последовательность имеет минимально возможную сложность К(s) = 1, так как для ее описания достаточно единственной инструкции.
Живительное следствие этого определения сложности состоит в том, что компьютеры не могут генерировать бесконечные случайные последовательности нулей и единиц. Интуитивно понятно, что последовательность является случайной, когда невозможно предсказать, каким будет ее следующий элемент. Это означает, что описание случайной последовательности не может быть короче, чем сама последовательность.
Иными словами, ее сложность бесконечно велика. Однако все компьютерные программы содержат конечное число инструкций (вспомните определение машины Тьюринга из предыдущей главы). Следовательно, генерируемые ими последовательности нулей и единиц, сколь случайными бы они ни казались, всегда будут иметь конечную сложность. Компьютеры могут воспроизводить только псевдослучайные последовательности, поэтому для генерирования истинно случайных последовательностей многие физики пытаются использовать недетерминированность атомов.
С другой стороны, определение сложности по Колмогорову во многом схоже с парадоксом библиотекаря, о котором мы рассказали в конце главы 2, где рассматривается множество натуральных чисел, которые можно описать пятнадцатью словами. Так как число фраз, состоящих из пятнадцати слов, является конечным, множество таких чисел также будет конечным. Следовательно, среди всех чисел, не принадлежащих этому множеству, можно определить наименьшее. Обозначим его за n. Однако в этом случае n будет «наименьшим числом, которое нельзя описать менее чем пятнадцатью словами» — это описание содержит всего девять слов!
Логично задаться вопросом, не приведет ли введенное нами определение сложности к противоречиям. Ответ удивляет: если бы функция К была вычислимой, то есть если бы существовала машина Тьюринга, способная вычислить для данной последовательности нулей и единиц s сложность К(s), то рассуждения, аналогичные тем, что мы использовали при решении проблемы остановки, позволили бы воспроизвести парадокс библиотекаря на формальном языке арифметики. Следовательно, единственно возможный ответ таков: сложность не является вычислимой, и этого достаточно для разрешения парадокса библиотекаря, который оставался открытым: выражение «описать пятнадцатью словами» некорректно, так как принадлежит не к языку, а к метаязыку.
Гёдель, Тьюринг и искусственный интеллект
На предыдущих страницах мы ограничились обсуждением приятия сложности исключительно с точки зрения математики, и читатель убедился, что определение этого понятия сопряжено с многочисленными трудностями. Наша изначальная цель была еще более амбициозной: мы хотели узнать, как измеряется сложность понятий «любовь» и «справедливость». Постепенно все новые и новые математические открытия вдохновили исследователей на создание новой теории сложности, которую можно обобщить фразой «целое больше, чем сумма его частей». Слова «сияние», «рана», «солнце» и «ближайший» имеют четкие значения — мы можем узнать их в словаре. Но когда французский поэт Рене Шар пишет «Сияние — рана, ближайшая к солнцу», из четырех прекрасно знакомых нам слов рождается нечто новое.
Стих представляет собой нечто большее, чем сумму слов, поэтому понять поэзию непросто.
Эта эмерджентность присуща не только языку — она характерна для так называемых общественных насекомых, с ее помощью объясняется успех интернета, и она является одним из ключей к изучению нервных систем живых существ. Представим себе, например, крохотного муравья, который в поисках пищи следует алгоритмам, заложенным в его генах. Мы никогда не смогли бы понять сложную организацию муравейника, способного приспосабливаться к экстремальным ситуациям, если бы рассматривали его исключительно как совокупность отдельных муравьев. Иммунная система также представляет собой нечто большее, чем совокупность клеток, экономика есть нечто большее, чем множество покупателей акций, а интернет — это нечто большее, чем сумма отдельных действий пользователей из разных уголков планеты. Понять, каким образом из относительной простоты отдельных компонентов этих систем возникает сложное единое целое — одна из величайших задач науки начала нынешнего столетия.
Хотя определение сложной системы как системы, в которой целое больше суммы его частей, довольно приблизительно, нет сомнений, что оно весьма точно описывает наш мозг. В этом случае отдельными компонентами системы являются нейроны — клетки, получающие импульсы, обрабатывающие их и передающие их другим нейронам посредством множества отростков. Среди исследователей мозга распространено мнение, согласно которому сеть связей, благодаря которым мозг становится чем-то большим, чем просто совокупностью отдельных нейронов, лежит в основе таких явлений, как восприятие, разум и чувства. А если бы мы могли воссоздать подобную структуру в информатике? Первые попытки математического моделирования нейронов упоминаются в статье, опубликованной в 1943 году, в которой невролог Уоррен Маккалок и логик Уолтер Питтс определили нейрон как функцию, которая на основе ряда входных значений выдает единственное выходное значение.
До этого момента все функции, рассмотренные в этой книге, имели единственное входное значение и преобразовывали его в другое значение посредством ряда операций. Однако в реальной жизни очень и очень немногие явления определяются всего одним параметром. Современная теория искусственных нейронных сетей, созданная на основе идей Питтса и Маккалока, позволяет имитировать работу мозга с помощью функций от нескольких параметров. Предположим, что мы хотим вычислить значение функции f, которое зависит от чисел х1, x2, … хn. Основная идея здесь заключается в том, что программа, в которую передаются эти числа, обрабатывает их подобно тому, как ядро нейрона обрабатывает электрические импульсы, поступающие по отросткам. Так как величина этих импульсов может отличаться, для каждого числа х нужно указать еще одно число, ил, которое называется весом и обозначает важность каждого электрического импульса по отношению к остальным. Например, если w1 и wn намного больше, чем w2, w3 … wn-1 это означает, что на результирующее значение оказывают наибольшее влияние первый и последний импульс. На основе весов импульсов в искусственной нейронной сети рассчитывается взвешенная сумма s = w1x1 + w2x2 + … + wnxn и находится значение функции, как показано на рисунке.
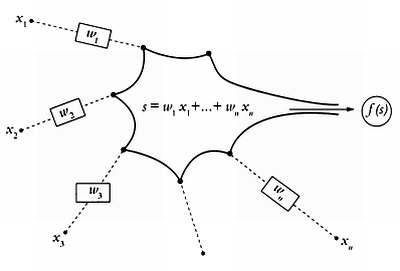
Новизна нейронных сетей заключается в том, что программа, с помощью которой мы хотим решить задачу, представляет собой не фиксированный, а открытый алгоритм, веса в котором могут изменяться. В действительности всякая нейронная сеть обычно проходит фазу обучения, на которой программа методом проб и ошибок «узнает», какие веса являются наиболее походящими, или, иными словами, какие входные сигналы следует учитывать в большей степени, чтобы итоговый результат был удовлетворительным. Если задача нашей нейронной сети заключается, например, в распознавании человеческого голоса и в ходе обучения выясняется, что большую часть первого импульса составляет фоновый шум, то сеть не будет придавать первому импульсу особого значения. Нейронные сети также очень эффективны при составлении метеорологических прогнозов и при решении задач, подобных задаче коммивояжера. Компьютеры, в которых используются нейронные сети и другие передовые алгоритмы, способны решить задачу коммивояжера уже для двухсот городов.
Благодаря нечеткой логике и нейронным сетям компьютеры, способные во многом имитировать деятельность человеческого мозга, перестали быть только частью научной фантастики. Решение новых задач стало главной целью новой, быстро развивающейся научной дисциплины — искусственного интеллекта. В течение многих лет считалось, что машина никогда не сможет играть в шахматы на уровне гроссмейстера. Вне зависимости от того, на сколько ходов вперед она способна просчитать игру, ей неизвестны слабые стороны противника, она не способна учесть иные психологические факторы. Машина не смогла бы обыграть человека и в азартные игры: как обучить компьютер игре в покер, если блеф противоречит очевидной выигрышной стратегии? Голоса критиков умолкли, когда в феврале 1996 года суперкомпьютер Deep Blue, ставший результатом работы компании IBM, начатой еще в 1950-е годы, обыграл Гарри Каспарова в первой партии шахматного матча. Затем, несмотря на то что Deep Blue мог оценивать сто миллионов позиций в секунду, из пяти следующих партий, которые игрались медленнее обычного, в четырех победу одержал российский шахматист. Однако годом позже машина была усовершенствована, и Deep Blue удалось одержать победу в трех партиях и еще одну — свести вничью, совершая ходы с той же скоростью, что и профессиональные шахматисты. Чемпион мира был повержен, однако это не помешало Каспарову по-прежнему отстаивать превосходство человека над машиной. Любопытно, что он приводил точно те же доводы, что и его противники, создавшие Deep Blue: «Это синтез, способность сочетать творчество и расчет, искусство и науку в единое целое, большее, чем сумма его частей».

Гарри Каспаров обдумывает очередной ход в партии против суперкомпьютера Deep Blue 10 мая 1997 года.
* * *
ДИАЛОГ ИЗ ФИЛЬМА «Я, РОБОТ»
(РЕЖИССЕР АЛЕКС ПРОЙАС, АВТОР СЦЕНАРИЯ ДЖЕФФ ВИНТАР, ПО ЦИКЛУ ПРОИЗВЕДЕНИЙ АЙЗЕКА АЗИМОВА, 2004)
Главный герой фильма, полицейский по фамилии Спунер, расследует убийство, в совершении которого он подозревает робота Санни.
Спунер: Теперь роботы могут и убивать. Прими поздравления. Отвечай!
Санни: Что это означает? (Мигает одним глазом.) Когда вы вошли и посмотрели на другого человека… Что это значит? (Вновь мигает одним глазом.)
Спунер: Это знак доверия. Это человеческое. Тебе не понять.
Санни: Отец учил меня человеческим эмоциям. Они… сложные.
Спунер: Ты хотел сказать, твой конструктор?
Санни: Да.
Спунер: Так зачем ты его убил?
Санни: Я не убивал доктора Лэннинга.
Спунер: А почему прятался на месте преступления?
Санни: Я боялся.
Спунер: Роботы не испытывают страха. Они вообще лишены чувств. Они не знают голода, им не нужен сон.
Санни: А мне нужен. Мне даже снятся сны.
Спунер: Только люди видят сны. Даже собаки их видят, а ты нет. Ты — просто машина. Имитация жизни. Может ли робот написать симфонию? Или создать шедевр живописи?
Санни: А вы можете?
* * *
Эти успехи привели к тому, что возобновились ожесточенные споры ученых и философов, начатые 50 годами ранее Куртом Геделем и Аланом Тьюрингом. Используя разные методы, Гедель и Тьюринг сформулировали одинаковые определения формальной системы и одинаково трактовали неразрешимые задачи. Однако Гёдель различал формализм и логику, механизм и разум, а Тьюринг считал эти понятия полностью синонимичными. Доведя это сравнение до предела, в 1947 году Тьюринг сформулировал следующий постулат: наилучшей моделью человеческого мозга является универсальная машина, способная имитировать поведение любой программы. Эту универсальную машину сам Тьюринг ввел, чтобы справиться с проблемой разрешения Гильберта. Тьюринг считал, что на вопрос о том, могут ли компьютеры мыслить, можно дать ответ только по итогам эксперимента. В написанной в 1950 году статье «Вычислительные машины и разум», название которой вошло в историю, Тьюринг предложил «игру в имитацию», чтобы ученые посредством ряда вопросов, передаваемых в письменном виде, могли определить, с кем они взаимодействуют — с человеком или компьютером. Суть теста заключалась в том, что если машина во всем ведет себя подобно разумному существу, то простейшее объяснение этому состоит в том, что она действительно является разумной.
Также Тьюринг предложил, чтобы претендента на звание разумного существа попросили написать стихотворение или выполнить сложные вычисления. По сути, успешное выполнение первого задания заставит предположить, что претендент — человек, а быстрый ответ на второй вопрос заставит думать, что перед нами — компьютер. Конечно, многие вообще не способны писать стихи или же стихи поэта-авангардиста могут напоминать случайный набор слов. Существуют и настоящие люди-«компьютеры», способные перемножать огромные числа или раскладывать их на множители с фантастической, машинной скоростью. Но несмотря на все эти трудности, все согласны с тем, что если мы можем задать неограниченное число вопросов, то всегда отличим человека от машины. Пока что тест Тьюринга не смог пройти ни один компьютер. Более того, этот тест используется и для распознавания спама, который, как правило, генерируется компьютерами.
В декабре 1969 года, спустя пятнадцать лет после смерти Тьюринга, Гёдель счел, что обнаружил в его работе ошибку, которая могла иметь серьезные последствия. Тьюринг не учел, что разум непрерывно развивается. Во время демонстрации формальные системы не претерпевают изменений, равно как и машины во время расчетов, однако ничто не может гарантировать, что живой разум не изменяется во время рассуждений. Следовательно, компьютер никогда не сможет заменить человеческий разум. В любой книге по искусственному интеллекту рано или поздно встречается раздел, посвященный аргументам Гёделя, однако они относятся не к описанной нами ситуации, а к идее оксфордского философа Джона Лукаса, согласно которой теоремы о неполноте в некотором роде имеют отношение к возможности изобретения разумных машин. Любопытно, что Гёдель никогда всерьез не думал о том, что его открытия имеют отношение к структуре человеческого разума.
Наиболее известный аргумент противников искусственного интеллекта, как мы уже сказали, принадлежит философу Джону Лукасу, который до того, как посвятить себя философии и древней истории, изучал математику. В статье «Разум, машины и Гедель», представленной в 1959 году Оксфордскому философскому обществу, Лукас удивительно простым языком объяснил, почему человеческий разум нельзя свести к компьютеру: так как мы способны обучить машину аксиомам и правилам вывода арифметики, мы можем составить все формулы языка и попросить машину определить, какие из них являются истинными. Рано или поздно компьютер дойдет до высказывания «эта фраза недоказуема» и проведет остаток вечности в попытках доказать или опровергнуть ее, в то время как мы, люди, немедленно поймем, что эта фраза является неразрешимой. «Следовательно, машина попрежнему не будет адекватной моделью разума <…> который будет всегда находиться на шаг впереди любой закостенелой, омертвевшей формальной системы», — заключал Лукас.
Прошло полвека, и уже почти никто не согласен ни с Джоном Лукасом, ни с его последователем, Роджером Пенроузом, который в 1989 году расширил и дополнил его точку зрения. Означает ли это, что мы, люди, видим истинность высказывания Гёделя? Первая теорема о неполноте гласит, что если арифметика является непротиворечивой, то высказывание «эта фраза недоказуема» является истинным, следовательно, чтобы определить его истинность, сначала необходимо определить непротиворечивость арифметики. Если мы примем непротиворечивость арифметики на веру, так как сочтем, что мир свободен от противоречий, то мы также сможем запрограммировать робота, в коде которого будет отражено ожидание того, что арифметика является непротиворечивой. Это не более чем одна из трактовок второй теоремы о неполноте, которая гласит, что непротиворечивость арифметики нельзя доказать в рамках ее формальной системы. Тем не менее, возражает Лукас, математики способны доказать непротиворечивость арифметики, обратившись к более сложным методам и языкам высших порядков. Да, мы способны выйти за рамки системы, в то время как у компьютера подобный шаг вызовет затруднения. Но что, если нам удастся обучить его этому? Что, если в очень сложной искусственной нейронной сети возникнут новые трактовки непротиворечивости? Ответ на этот вопрос не так прост, как может показаться.
Что подумал бы Евклид об отходе от аксиоматического метода? Дополнение аксиоматического метода нечеткой логикой XXI века стало бы прекрасным финалом этого романа, который начался с открытия неевклидовой геометрии, продолжился теорией множеств и ее парадоксами, а в последующих его главах на первый план вышли три героя: Давид Гильберт, Курт Гёдель и Алан Тьюринг. Это было бы прекрасным завершением нашей книги, но исследования математиков и логиков на этом не заканчиваются. За те несколько месяцев, которые пройдут, прежде чем эта книга попадет к первым читателям, математики, физики и инженеры еще больше усовершенствуют нейронные сети. Нечеткая логика, возможно, возьмет новый курс, и, быть может, кому-то удастся найти решение проблемы равенства классов Р и NP. Поэтому будет лучше, если сейчас мы поставим точку. Хорошо кончается то, что не кончается, — эта фраза станет неплохим финалом книги, главными героями которой являются парадоксы.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
Глава 7 Запоминающаяся глава для запоминания чисел[9]
Глава 7 Запоминающаяся глава для запоминания чисел[9] Наиболее часто мне задают вопрос о моей памяти. Нет, сразу скажу я вам, она у меня не феноменальная. Скорее, я применяю систему мнемотехники, которая может быть изучена любым человеком и описана на следующих страницах.
Глава 1
Глава 1 Кто Джон? Для того чтобы узнать, кого из двух братьев-близнецов зовут Джон, нужно спросить одного из них: «Джон говорит правду?». Если в ответ на этот вопрос последует «да», то независимо от того, лжет ли спрошенный близнец или говорит всегда только правду, он должен
Глава 2
Глава 2 1. История первая. По существу, Болванщик заявил, что варенье украли либо Мартовский Заяц, либо Соня. Если Болванщик солгал, то ни Мартовский Заяц, ни Соня не украли варенье. Но тогда Мартовский Заяц, поскольку он не украл варенье, дал правдивые показания.
Глава 3
Глава 3 14. Гусеница и Ящерка Билль. Гусеница считает, что и она, и Ящерка Билль не в своем уме. Если бы Гусеница была в здравом уме, то мнение о том, что и она, и Ящерка Билль не в своем уме, было бы ложно. Следовательно, Гусеница (будучи в здравом уме) не могла бы придерживаться
Глава 4
Глава 4 26. Сколько кренделей у каждого? Назовем одной порцией все крендельки, которые достались Соне, сколько бы их ни было. Тогда Соне досталась 1 порция. Мартовскому Зайцу досталось вдвое больше крендельков, чем Соне (потому что Соню Болванщик посадил на такое место, где
Глава 5
Глава 5 42. Появление первого шпиона. С заведомо не может быть рыцарем, так как ни один рыцарь не стал бы лгать и утверждать, будто он шпион. Следовательно, С либо лжец, либо шпион. Предположим, что С шпион. Тогда показание А ложно, значит, А шпион (А не может быть шпионом, так
Глава 6
Глава 6 52. Первый вопрос. Алиса ошиблась, записав одиннадцать тысяч одиннадцать сотен и одиннадцать как 11111, что неверно! Число 11111 – это одиннадцать тысяч одна сотня и одиннадцать! Для того чтобы понять, как правильно записать делимое, сложим одиннадцать тысяч,
Глава 7
Глава 7 64. Первый раунд (Красное н черное). Если внезапно заговоривший братец сказал правду, то его звали бы Траляля и в кармане у него была бы черная карта. Но тот, у кого в кармане карта черной масти, не может говорить правду. Следовательно, он лжет. Значит, в кармане у него
Глава 9
Глава 9 Во всех решениях этой главы А означает первого подсудимого, В – второго и С – третьего.78. Кто виновен? Из условий задачи известно, что виновный дал ложные показания. Если бы В был виновен, то он сказал бы правду, когда признал виновным себя. Следовательно, В не может
Глава 11
Глава 11 88. Всего лишь один вопрос. Действительно следуют. Рассмотрим сначала утверждение 1. Предположим, некто убежден, что он бодрствует. В действительности он либо бодрствует, либо не бодрствует. Предположим, что он бодрствует. Тогда его убеждение правильно, но всякий,
Глава 1
Глава 1 graphics46 Кто Джон?Чтобы узнать, кто из двух братьев Джон, спросите одного из них: «Джон правдив?» Если он ответит «да», это должен быть Джон, независимо от того, солгал он или сказал правду. Если же он ответит «нет», значит, он не Джон. И вот как это подтверждается.Ответив
Глава 2
Глава 2 graphics48 1. История перваяШляпник заявил, по существу, что повидло украл либо Мартовский Заяц, либо Соня. Если Шляпник солгал, значит ни Мартовский Заяц, ни Соня повидла не крали. Раз Мартовский Заяц кражи не совершал, то он, следовательно, сказал на суде правду.
Глава 3
Глава 3 graphics50 14. Гусеница и Ящерка БилльГусеница убеждена в том, что и она, и Ящерка Билль оба не в своем уме. Если бы Гусеница была в своем уме, то ее суждение о том, что оба они из ума выжили, было бы ложным. Раз так, то Гусеница (будучи в своем уме) вряд ли всерьез могла быть
Глава 9
Глава 9 Для всех решений в этой главе назовем первого подсудимого А, второго — Б и третьего — В. graphics56 78. Кто виновен?Нам дано, что солгал тот, кто был виновен. Если бы это был Б, он сказал бы правду, признав свою вину, поэтому Б не может быть виновным. Если бы виновным был А, то